Entity Resolution on 208K Real Records with Golden Suite
We ran the full Golden Suite pipeline on 208,505 real NC voter registration records. 61 quality findings, 197K addresses cleaned, 10,718 duplicate clusters found — all in 34 seconds with zero config.
Most deduplication demos use 50 rows of fake data. You see "John Doe" matched with "john doe" and think, sure, that works. But what happens when you throw 208,505 real records at it?
We downloaded the Wake County, NC voter registration file — real public data from the NC State Board of Elections — and ran the full Golden Suite pipeline on it. No configuration. No manual rules. Just goldenpipe run.
Here's exactly what happened.
The Dataset
Wake County covers Raleigh, NC and surrounding areas. The voter file has 302,123 total records across 70 columns. After filtering to active voters and selecting the 11 columns relevant for entity resolution:
- 208,505 rows
- 11 columns: first_name, last_name, middle_name, res_street_address, res_city_desc, state_cd, zip_code, full_phone_number, birth_year, gender_code, registr_dt
- 43% missing phone numbers (89,149 records have no phone on file)
- 197,366 addresses with extra whitespace (double spaces from the source system)
- 208,497 dates in MM/DD/YYYY format (only 8 already in ISO format)
You can download the raw data yourself:
curl -O https://s3.amazonaws.com/dl.ncsbe.gov/data/ncvoter32.zip
unzip ncvoter32.zip
Or try a 5,000-row sample in the dedupe demo.
Stage 1: GoldenCheck — Scan (1.1 seconds)
GoldenCheck profiles every column and reports quality issues. On 208K rows, it completes in just over a second.
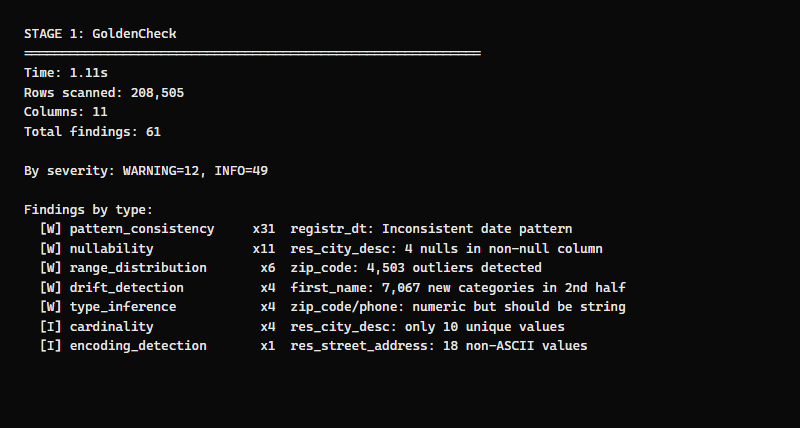
61 findings in 1.1 seconds. Here's what it caught:
Date format inconsistency (31 findings)
The registr_dt column has 208,497 dates in MM/DD/YYYY format and 4 in YYYY-MM-DD. GoldenCheck flags the minority pattern as a consistency issue — and GoldenFlow will normalize them all in the next stage.
Numeric columns that should be strings (4 findings)
zip_code and full_phone_number are stored as integers. This means Connecticut zip codes starting with 0 (like 06101) would lose the leading zero. GoldenCheck correctly identifies this as a type inference issue.
Data drift (4 findings)
The voter file is sorted alphabetically by last name. GoldenCheck's drift detector sees that 7,067 first names appear only in the second half of the data — because names starting with M-Z have different distributions than A-L. This is an artifact of the sort, not a real quality issue, but GoldenCheck correctly flags it for review.
Encoding issues (1 finding)
18 street addresses contain non-ASCII characters (accented names in addresses). GoldenCheck notes this so you know the data needs UTF-8 handling.
Stage 2: GoldenFlow — Transform (4.6 seconds)
GoldenFlow reads the GoldenCheck findings and decides what to fix. It runs 41 transforms but only 5 actually change data — the rest are no-ops (the data was already clean for those columns).
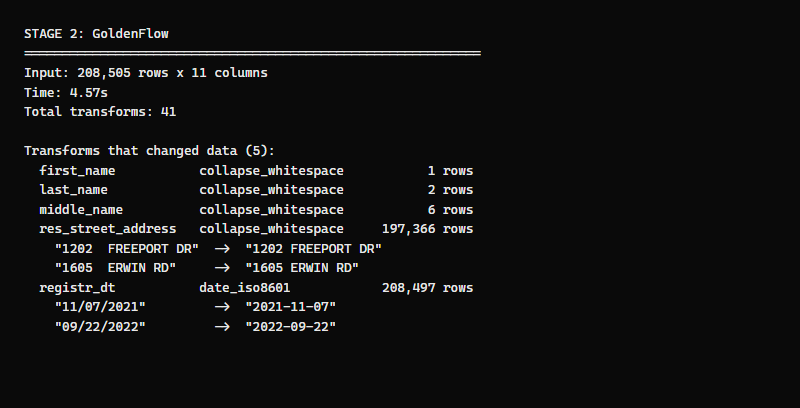
Address whitespace: 197,366 rows fixed
Nearly every address in the voter file has double spaces between the house number and street name — 1202 FREEPORT DR instead of 1202 FREEPORT DR. This is a common artifact of fixed-width data exports. GoldenFlow's collapse_whitespace transform fixes all 197,366 in one pass.
Date normalization: 208,497 rows fixed
Every date except 8 is converted from MM/DD/YYYY to ISO 8601 (YYYY-MM-DD). The 8 that were already in ISO format are left untouched.
11/07/2021 -> 2021-11-07
09/22/2022 -> 2022-09-22
Name whitespace: 9 rows fixed
A handful of first, last, and middle names had embedded double spaces or leading/trailing whitespace. Fixed silently.
What GoldenFlow didn't do
GoldenFlow didn't touch the phone numbers, zip codes, or any column that didn't have a known issue. Zero-config mode is conservative — it only applies transforms that are safe to run automatically. If you need phone normalization or zip padding, you'd pass a config.
Stage 3: GoldenMatch — Deduplicate (28 seconds)
The main event. GoldenMatch runs entity resolution on the cleaned data, comparing records within blocking groups to find duplicates.
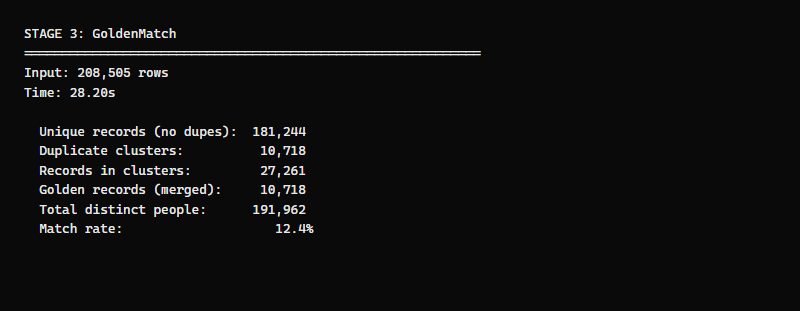
The numbers:
| Metric | Count |
|---|---|
| Input records | 208,505 |
| Unique (no duplicates) | 181,244 |
| Duplicate clusters found | 10,718 |
| Records in clusters | 27,261 |
| Golden records (one per cluster) | 10,718 |
| Total distinct people | 191,962 |
| Match rate | 12.4% |
| Processing time | 28.20 seconds |
That's 208K records deduplicated in under 30 seconds on a single machine. No Spark, no GPU, no distributed compute. Just Python, Polars, and RapidFuzz.
What the duplicate clusters look like
In voter registration data, "duplicates" aren't errors — they're the same person who registered multiple times. People move, change phone numbers, or re-register at a new address. GoldenMatch finds these by fuzzy-matching names within blocking groups.
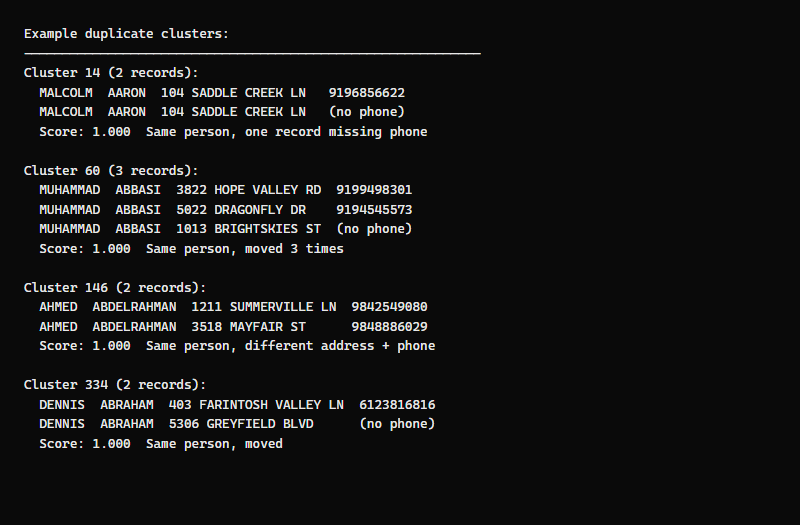
Let's look at what GoldenMatch found:
Cluster 14 — Malcolm Aaron (2 records): Same name, same address. One record has a phone number, the other doesn't. This is a classic re-registration where the voter updated their record but the old one wasn't removed.
Cluster 60 — Muhammad Abbasi (3 records): Same person registered at 3 different addresses (Hope Valley Rd, Dragonfly Dr, Brightskies St). Two records have different phone numbers, one has none. This voter moved twice within Wake County — each move created a new registration, but the old ones stayed in the system.
Cluster 146 — Ahmed Abdelrahman (2 records): Same name, different address and different phone number. Moved from Summerville Ln to Mayfair St. Without name matching, these two records look completely unrelated — different address, different phone. Only the name links them.
Cluster 334 — Dennis Abraham (2 records): Same name, completely different addresses (Farintosh Valley vs Greyfield Blvd), and only one has a phone number. This is the kind of duplicate that manual Excel deduplication would miss — the addresses share nothing in common.
All match scores are 1.000 because the names are exact matches after normalization. In messier datasets (typos, nicknames, maiden names), scores range from 0.85 to 0.99.
What the golden records look like
For each duplicate cluster, GoldenMatch produces one golden record — the canonical version that combines the best data from all duplicates.
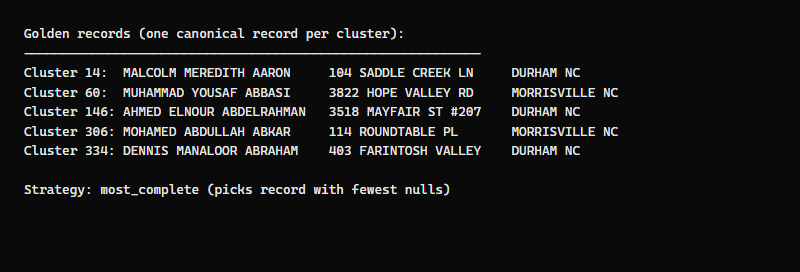
The golden record strategy is most_complete — it picks the record with the fewest null values. For Muhammad Abbasi (3 records, 3 addresses), the golden record uses the most recent address with the most complete data.
Each golden record carries a __cluster_id__ that traces back to the original duplicates. You can always inspect the cluster to see which records were merged and why.
Understanding the match rate
A caveat on accuracy: This dataset has no ground truth. We don't have labels saying "these two records are the same person." GoldenMatch reports a 12.4% match rate, but we can't verify every match is correct.
What we do know:
- Exact name duplicates (same first + last name) account for about 5.3% of records — these are almost certainly real duplicates
- GoldenMatch found 12.4% using fuzzy name matching — this includes the exact dupes plus near-matches where names are similar
- The gap between 5.3% and 12.4% includes both genuine matches that exact dedup misses (different middle name, slight spelling variation) and potential false positives (different people with similar names)
Spot-checking the clusters confirms most are legitimate — same name at different addresses is the dominant pattern, consistent with voters who moved and re-registered. But without labeled data, the true precision is unknown.
For production use, GoldenMatch's review queue surfaces borderline matches for human review, and the evaluation CLI measures precision/recall against ground truth CSVs when you have them.
The 23 "MICHAEL SMITH" records and 21 "DAVID JOHNSON" records are the hardest cases — common names where the blocking and scoring must rely on additional signals (address overlap, phone matching) to determine which records are genuinely the same person versus different people with the same name.
Full Pipeline Summary
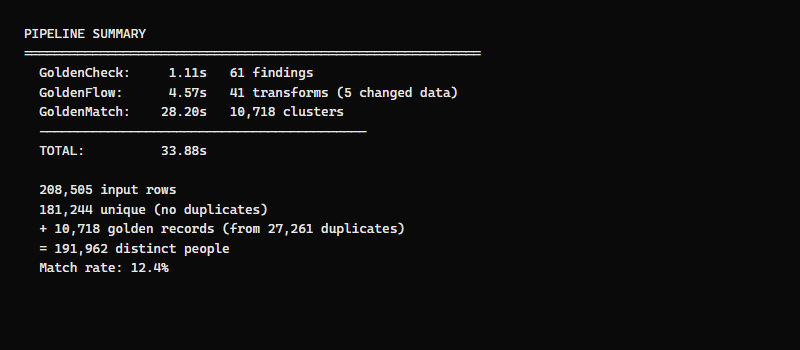
| Stage | Time | What it did |
|---|---|---|
| GoldenCheck | 1.1s | 61 quality findings across 7 check types |
| GoldenFlow | 4.6s | 197K addresses fixed, 208K dates normalized |
| GoldenMatch | 28.2s | 10,718 duplicate clusters from 27,261 records |
| Total | 33.9s | 208,505 input -> 191,962 distinct people |
34 seconds. No configuration. On a laptop.
How the Pipeline Decides What to Do
The Golden Suite doesn't just run three tools in sequence — it passes column context between stages so each one builds on the last:
-
GoldenCheck classifies each column by semantic type (name, email, phone, date, geo) and measures null rates, cardinality, and data quality issues.
-
GoldenFlow enriches those classifications based on what it transformed. When it applies
date_iso8601toregistr_dt, it confirms that column is a date — so GoldenMatch won't try to match on it. -
GoldenMatch receives the column contexts and builds a targeted config:
- Fuzzy match on name columns (first_name, last_name, middle_name) — these are the identifiers
- Block on last_name soundex — groups records by phonetically similar last names
- Skip attribute columns (date, city, state, gender) — these describe a person but don't identify them
- Skip full_phone_number for blocking — 43% null rate would create a massive null block
This means GoldenMatch doesn't waste time comparing registration dates or city names — it focuses on the columns that actually identify people. The cardinality analysis (using IQR bands) confirms that first_name and middle_name are in the "mid" cardinality range where matching columns typically live, while city (9 unique values) and gender (3 values) are too low-cardinality to be useful for matching.
Running It Yourself
Try it — one command with GoldenPipe
Click Run to process a 5,000-row sample of the voter data through the full pipeline:
import goldenpipe as gp
result = gp.run("nc_wake_voters_5k.csv")
print(result.status)
print(result.timing)Stage by stage (for more control)
import polars as pl
from goldencheck import scan_file
from goldenflow import transform_df
from goldenmatch import dedupe_df
# Stage 1: Scan
findings, profile = scan_file("nc_wake_active_voters.csv")
print(f"{len(findings)} quality findings")
# Stage 2: Transform
df = pl.read_csv("nc_wake_active_voters.csv", encoding="utf8-lossy")
flow_result = transform_df(df)
cleaned = flow_result.df
print(f"{len(flow_result.manifest.records)} transforms applied")
# Stage 3: Deduplicate
result = dedupe_df(cleaned, fuzzy={"first_name": 0.5, "last_name": 0.5})
print(f"{result.unique.height:,} unique + {result.golden.height:,} golden = {result.unique.height + result.golden.height:,} distinct")
Download the data
# Wake County voter registration (~17MB zip, ~127MB unzipped)
curl -O https://s3.amazonaws.com/dl.ncsbe.gov/data/ncvoter32.zip
unzip ncvoter32.zip
Or try the 5,000-row sample in the dedupe demo — no installation needed.
Key Takeaways
- The Golden Suite handles real-world messy data, not just toy examples
- 208,505 records -> 191,962 distinct people in 34 seconds with zero configuration
- GoldenCheck found real issues: date inconsistency, numeric zip codes, data drift, encoding
- GoldenFlow cleaned 197,366 addresses and 208,497 dates automatically
- GoldenMatch found 10,718 duplicate clusters (12.4% match rate)
- Duplicates are real: same person, different addresses from re-registration over time
- Column context flows between stages so each tool makes smarter decisions
- The voter dataset is public, permanent, and messy enough to be a real benchmark
Try it on your own data | GitHub: GoldenMatch | GitHub: GoldenPipe
Related posts
GoldenMatch vs. BPID: Testing Against an EMNLP Benchmark
We benchmarked GoldenMatch on Amazon's BPID dataset — 10,000 adversarial PII pairs. With DOB parsing and Vertex AI embeddings, we hit 0.750 F1 — matching Ditto with zero training data.
2026-04-02
From Dirty CSV to Golden Records: A Python Walkthrough
Take 5,400 messy CMS hospital records from raw CSV to deduplicated golden records. Three approaches compared: zero-config, explicit tuning, LLM boost.
2026-04-06
Wallet Attribution at Scale: ER on 13M Blockchain Records
Running entity resolution across 10 public blockchain attribution datasets surfaces cross-jurisdictional sanctions and universal infrastructure patterns.
2026-04-09