Product Catalog Dedup on a Real 1M-Row Dataset: F1 0.05 → 0.36 in Three Steps
Running the full Golden Suite (GoldenCheck → GoldenFlow → GoldenMatch) on the UCI Online Retail II catalog. Real, unsynthetic duplicates. Honest numbers — and how fixing the eval, switching to Vertex AI embeddings, and tuning the threshold lifted F1 7× from a hopeless lexical baseline.
A wholesaler's product catalog is one of the dirtiest tables in any retail business. The same SKU shows up as 'DOILEY STORAGE TIN', 'STORAGE TIN VINTAGE DOILEY ', and 'STORAGE TIN VINTAGE DOILY ' (note the missing E) — three rows in your database for the same physical product. Multiply by every typo, abbreviation, and product rename across two years and your "5,000-product catalog" is actually 4,000 distinct products plus 1,000 ghost rows.
This post takes the UCI Online Retail II dataset — 1,067,371 transactions from a UK-based online wholesaler between 2009 and 2011 — and runs the full Golden Suite (GoldenCheck → GoldenFlow → GoldenMatch) against the real, unsynthetic duplicates hiding in its product catalog. No injected dirty data. The dataset comes pre-broken.
This is also a post about what you can honestly expect from automated dedup on real, messy production data. The first config I tried produced an embarrassing F1 of 0.05. The path from there to F1 = 0.36 is the actual story — three concrete fixes, each measured, each justified, with the limits at the end. Spoiler: the biggest single improvement isn't a fancier matcher, it's fixing the metric.
The Dataset
The UCI Online Retail II dataset contains every transaction for a UK-based online wholesaler of gift-ware between 01/12/2009 and 09/12/2011 — a 14 MB CSV available on Kaggle (mirror of the UCI archive).
import polars as pl
df = pl.read_csv(
"online_retail_II.csv",
schema_overrides={"Invoice": pl.Utf8, "StockCode": pl.Utf8, "Customer ID": pl.Utf8},
)
print(df.shape)
# (1067371, 8)
From line items to products
Each row is a line item, not a transaction or a product. The full hierarchy:
| Level | Count |
|---|---|
| Raw rows (line items) | 1,067,371 |
| Unique invoices | 53,628 |
| Unique customers | 5,943 |
| Unique products (StockCode) | 4,950 |
About 20 line items per invoice (it's a wholesale order — people buy lots of one thing) and ~9 invoices per customer over two years.
For product dedup, I want one row per unique (StockCode, Description) combination, with a numeric fingerprint to disambiguate later.
clean = df.filter(
pl.col("Description").is_not_null() &
(pl.col("Price") > 0) &
(pl.col("Quantity") != 0) &
~pl.col("Invoice").str.starts_with("C") # drop cancellations
)
product_frame = (
clean
.group_by(["StockCode", "Description"])
.agg([
pl.len().alias("n_rows"),
pl.col("Price").mean().round(2).alias("avg_price"),
pl.col("Quantity").median().alias("median_qty"),
pl.col("InvoiceDate").min().alias("first_seen"),
pl.col("InvoiceDate").max().alias("last_seen"),
])
.with_row_index("row_id")
)
print(product_frame.shape)
# (5630, 11)
5,630 unique (StockCode, Description) combinations out of 1.04M filtered transactions. 4,917 unique StockCodes, 5,399 unique Descriptions.
The descriptions-per-StockCode distribution
| Descriptions per StockCode | Count |
|---|---|
| 1 | 4,269 (87%) |
| 2 | 591 |
| 3 | 49 |
| 4 | 8 |
87% of SKUs are clean. 648 SKUs have multiple descriptions — the natural test set, no synthesis needed.
What dirty SKUs actually look like
StockCode 23236:
[ 13 rows, GBP 2.86] 'DOILEY BISCUIT TIN'
[ 123 rows, GBP 3.10] 'DOILEY STORAGE TIN'
[ 2 rows, GBP 4.34] 'STORAGE TIN VINTAGE DOILEY '
[ 201 rows, GBP 3.39] 'STORAGE TIN VINTAGE DOILY '
StockCode 22852:
[ 155 rows, GBP 4.56] 'DOG BOWL VINTAGE CREAM'
[ 2 rows, GBP 4.25] 'DOG BOWL, ENAMEL , CREAM COLOUR'
[ 3 rows, GBP 4.21] 'ENAMEL DOG BOWL CREAM'
StockCode 22345:
[ 87 rows, GBP 0.68] 'PARTY PIZZA DISH BLUE POLKADOT'
[ 28 rows, GBP 0.97] 'PARTY PIZZA DISH BLUE RETROSPOT'
[ 17 rows, GBP 1.24] 'PARTY PIZZA DISH BLUE WHITE SPOT '
Five distinct phenomena visible just here:
- Pure typos (
DOILEY↔DOILY, missing E) - Punctuation drift (
FONT 7↔FONT, 7) - Word reordering (
DOG BOWL VINTAGE CREAM↔ENAMEL DOG BOWL CREAM) - Pattern renames with price changes (
POLKADOT↔RETROSPOT↔WHITE SPOT, GBP 0.68/0.97/1.24) - Trailing whitespace everywhere
The pattern-rename case is the philosophical hard one: are 'PARTY PIZZA DISH BLUE POLKADOT' and 'PARTY PIZZA DISH BLUE RETROSPOT' the same product? Same StockCode says yes. Different marketing name and different price says no. The answer depends entirely on what you're trying to do with the deduped data, and that ambiguity will haunt every metric I compute.
Ground truth comes for free — almost
Here's the trick: StockCode is the ground truth. Two rows with the same StockCode are by definition the same product. So if I dedupe purely on Description strings and recover the StockCode groupings, I have a fully-labeled evaluation set with no manual labeling.
gt_pairs = set()
by_code = product_frame.group_by("StockCode").agg(pl.col("row_id"))
for row in by_code.iter_rows(named=True):
rids = sorted(row["row_id"])
for i in range(len(rids)):
for j in range(i+1, len(rids)):
gt_pairs.add((rids[i], rids[j]))
print(len(gt_pairs))
# 786
786 ground truth pairs. Hold this number — we'll come back to it when I prove it's wrong.
I save StockCode in a separate file and never expose it to the matcher. The matcher only sees Description and the numeric fingerprint columns.
Stage 1: GoldenCheck
import goldencheck
findings, profile = goldencheck.scan_file("products.csv")
print(f"{profile.row_count} rows, {profile.column_count} cols")
print(f"{len(findings)} findings (severity: {sev_counts})")
5630 rows, 10 cols
35 findings (9 WARNING, 26 INFO)
range_distribution: 13 (numeric outliers in price/qty)
nullability: 10
pattern_consistency: 6 (mixed case, trailing whitespace in Description)
drift_detection: 3 (date column distributions shift over the 2-year period)
type_inference: 1
uniqueness: 1
encoding_detection: 1
Total time: 0.2s. GoldenCheck doesn't fix anything — it hands findings to GoldenFlow.
Stage 2: GoldenFlow
import goldenflow
from goldenflow.config.schema import GoldenFlowConfig, TransformSpec
config = GoldenFlowConfig(transforms=[
TransformSpec(column="Description", ops=["strip", "upper_case"]),
])
result = goldenflow.transform_df(df, config=config)
cleaned = result.df
0.08s. 1,011 cells affected — almost all of them stripping trailing whitespace from Description. That's 18% of the catalog, fixed in a millisecond.
BEFORE: 'INFLATABLE POLITICAL GLOBE '
AFTER: 'INFLATABLE POLITICAL GLOBE'
Trailing whitespace alone makes 18% of the rows look unique to a string matcher when they aren't. Free precision win.
Stage 3: GoldenMatch — The Honest Iteration
I'll walk through five configurations in order. Each one improves on the last, and the final result is F1 = 0.358 — a 7× lift from the F1 = 0.053 starting point. All five evaluated with gm.evaluate_clusters against the StockCode-derived ground truth (and yes, we'll fix that ground truth halfway through).
Run 1: Zero-config
import goldenmatch as gm
result = gm.dedupe_df(cleaned)
e = gm.evaluate_clusters(result.clusters, gt_pairs)
print(f"P={e.precision:.3f} R={e.recall:.3f} F1={e.f1:.3f}")
| Metric | Value |
|---|---|
| Multi-member clusters | 616 |
| TP / FP / FN | 121 / 4,040 / 665 |
| Precision | 0.029 |
| Recall | 0.154 |
| F1 | 0.049 |
| Time | 49.9s |
The auto-config picks scorers and blocking suited for typical name/address dedup, not short product strings. It builds 616 clusters with sizes up to 28 — clear over-merging. F1 = 0.049 is essentially random.
Run 2: Explicit lexical config
from goldenmatch.config.schemas import (
GoldenMatchConfig, BlockingConfig, BlockingKeyConfig,
MatchkeyConfig, MatchkeyField, StandardizationConfig,
)
config = GoldenMatchConfig(
standardization=StandardizationConfig(rules={"Description": ["trim_whitespace"]}),
blocking=BlockingConfig(
strategy="multi_pass",
keys=[BlockingKeyConfig(fields=["Description"], transforms=["lowercase", "substring:0:4"])],
passes=[
BlockingKeyConfig(fields=["Description"], transforms=["lowercase", "substring:0:4"]),
BlockingKeyConfig(fields=["Description"], transforms=["lowercase", "first_token"]),
BlockingKeyConfig(fields=["Description"], transforms=["lowercase", "first_token", "soundex"]),
],
max_block_size=200,
skip_oversized=True,
),
matchkeys=[
MatchkeyConfig(
name="product_match",
type="weighted",
threshold=0.88,
fields=[
MatchkeyField(field="Description", scorer="ensemble", weight=1.0,
transforms=["lowercase", "strip"]),
],
),
],
)
result = gm.dedupe_df(cleaned, config=config)
Three blocking passes (4-char prefix, first token, first-token soundex), ensemble scorer (max of jaro_winkler / token_sort / soundex / dice).
| Metric | Zero-Config | Explicit Lexical |
|---|---|---|
| TP / FP / FN | 121 / 4,040 / 665 | 449 / 15,653 / 337 |
| Precision | 0.029 | 0.028 |
| Recall | 0.154 | 0.571 |
| F1 | 0.049 | 0.053 |
| Time | 49.9s | 1.3s |
Recall jumped from 0.15 to 0.57. But false positives exploded to 15,653 — one cluster has 69 members. The lexical matcher chained unrelated products through shared common tokens: 'PINK MUG' matches 'PINK BAG' (token_sort sees them as 50% similar), 'PINK BAG' matches 'PINK BOX', and the connected component grows.
This is the fundamental problem with lexical matching on short product names: too many products share too many words.
Run 3: + LLM iterative calibration
The instinct is to throw GPT-4o-mini at it:
from goldenmatch.config.schemas import LLMScorerConfig, BudgetConfig
config_llm = GoldenMatchConfig(
standardization=config.standardization,
blocking=config.blocking,
matchkeys=config.matchkeys,
llm_scorer=LLMScorerConfig(
enabled=True,
provider="openai",
model="gpt-4o-mini",
auto_threshold=0.92,
candidate_lo=0.55,
candidate_hi=0.92,
calibration_sample_size=100,
budget=BudgetConfig(max_cost_usd=0.50, max_calls=500),
),
)
| Metric | Lexical | + LLM |
|---|---|---|
| TP / FP / FN | 449 / 15,653 / 337 | 449 / 15,653 / 337 |
| F1 | 0.053 | 0.053 |
| Time | 1.3s | 34.8s |
No change. Why? Because the GoldenMatch LLM scorer can only promote borderline pairs to matches; it never demotes pairs that already crossed the fuzzy threshold. All 15,653 false positives scored above 0.88 from the lexical matcher and were already accepted before the LLM saw anything.
This is an honest architectural limit: LLM scoring is designed to recover missed matches, not filter false ones. To fix over-clustering you need a different mechanism — better blocking, tighter scorer, or smarter representations. Which leads to:
Run 4: ANN blocking + embedding scorer (Vertex AI)
The right tool for short, semantically-rich product names is embeddings. 'PINK MUG' and 'PINK BAG' are lexically 50% similar but semantically very different — a sentence embedding model knows that MUG and BAG refer to different object categories regardless of how they're spelled.
GoldenMatch supports embedding-based blocking and scoring out of the box. With GOLDENMATCH_GPU_MODE=vertex set, it routes embedding calls through Vertex AI's text-embedding-004 instead of running a local sentence-transformer:
gcloud auth application-default login
export GOLDENMATCH_GPU_MODE=vertex
export GOOGLE_CLOUD_PROJECT=your-project-id
config = GoldenMatchConfig(
standardization=StandardizationConfig(rules={"Description": ["trim_whitespace"]}),
blocking=BlockingConfig(
strategy="ann", # FAISS nearest-neighbor on embeddings
ann_column="Description",
ann_top_k=10,
max_block_size=50,
),
matchkeys=[
MatchkeyConfig(
name="product_match",
type="weighted",
threshold=0.92,
fields=[
MatchkeyField(
field="Description",
scorer="embedding", # cosine similarity of embeddings
weight=1.0,
transforms=["lowercase", "strip"],
),
],
),
],
)
Three things change vs. the lexical config:
- Blocking strategy
ann: embed every Description once, build a FAISS index, fetch the 10 nearest neighbors per row. No more "everything starting with PINK" mega-blocks. - Scorer
embedding: cosine similarity of the embedding vectors instead of edit distance. - Threshold 0.92: cosine similarities for short text tend to land in a narrower band than fuzzy ratios.
| Metric | Lexical | LLM | Embedding |
|---|---|---|---|
| TP / FP / FN | 449 / 15,653 / 337 | 449 / 15,653 / 337 | 427 / 1,847 / 359 |
| Precision | 0.028 | 0.028 | 0.188 |
| Recall | 0.571 | 0.571 | 0.543 |
| F1 | 0.053 | 0.053 | 0.279 |
| Time | 1.3s | 34.8s | 271.7s |
False positives drop from 15,653 to 1,847 — an 88% reduction with only a tiny drop in recall. F1 jumps 5× from 0.053 to 0.279. Cluster sizes also collapse: max cluster size goes from 69 (lexical) to 22 (embedding).
The 271-second runtime is the cost of embedding 5,630 unique strings via the Vertex API. For larger catalogs you'd cache the embeddings — GoldenMatch reuses them across runs.
A look at the "false positives"
Before pushing the matcher harder, look at what it's getting "wrong":
[82613A] 'METAL SIGN,CUPCAKE SINGLE HOOK'
[82613C] 'METAL SIGN,CUPCAKE SINGLE HOOK' ← byte-identical, different sub-SKU
[40001] 'WHITE BAMBOO RIBS LAMPSHADE'
[40003] 'WHITE BAMBOO RIBS LAMPSHADE' ← byte-identical, different sub-SKU
The matcher correctly identified these as duplicates. The StockCode-based ground truth wrongly says they aren't because the wholesaler assigned them sub-suffixed codes (82613A vs 82613C). These are real catalog dedup wins that the metric punishes.
Which brings us to the biggest improvement of all.
Run 5: Fix the eval (normalize StockCodes)
What if the ground truth itself is wrong? Let me strip trailing letter suffixes from the StockCodes and rebuild the GT:
import re
def normalize_stockcode(code):
# 82613A → 82613, 85123a → 85123, 47566B → 47566
return re.sub(r"[A-Za-z]$", "", str(code))
ev = ev.with_columns(
pl.col("StockCode").map_elements(normalize_stockcode, return_dtype=pl.Utf8).alias("StockCode_norm")
)
# Rebuild GT from normalized codes
gt_v2 = set()
by_code = ev.group_by("StockCode_norm").agg(pl.col("row_id"))
for row in by_code.iter_rows(named=True):
rids = sorted(row["row_id"])
for i in range(len(rids)):
for j in range(i+1, len(rids)):
gt_v2.add((rids[i], rids[j]))
print(f"GT v1 (raw): {len(gt_pairs)} pairs")
print(f"GT v2 (normalized): {len(gt_v2)} pairs")
GT v1 (raw): 786 pairs
GT v2 (normalized): 4057 pairs
4,057 ground truth pairs vs the original 786. Stripping trailing letters from StockCodes added 3,271 new same-product pairs that the original metric was treating as different products. Many of these are sub-SKUs (82613A/82613C) that share an identical Description. The matcher was finding them all along — they were just being scored as false positives.
Re-evaluating the same embedding run against the new GT, with no recompute:
| Metric | Embedding (GT v1) | Embedding (GT v2) |
|---|---|---|
| TP | 427 | 910 |
| FP | 1,847 | 1,364 |
| FN | 359 | 3,147 |
| Precision | 0.188 | 0.400 |
| Recall | 0.543 | 0.224 |
| F1 | 0.279 | 0.288 |
Precision more than doubles (0.188 → 0.400) just by using a less broken metric. Recall drops because the denominator grew 5× — there are now many more pairs to find — but F1 still improved. The 1,364 remaining FPs are mostly cross-StockCode collisions (different products with the same description) which is a separate, harder problem.
Run 6: Threshold sweep
Now that the eval is honest, I can tune the threshold properly. Three runs of the same embedding config at thresholds 0.88, 0.92, 0.95:
| Threshold | GT | TP | FP | FN | Precision | Recall | F1 |
|---|---|---|---|---|---|---|---|
| 0.88 | v2 | 1,711 | 3,794 | 2,346 | 0.311 | 0.422 | 0.358 |
| 0.92 | v2 | 910 | 1,364 | 3,147 | 0.400 | 0.224 | 0.288 |
| 0.95 | v2 | 545 | 628 | 3,512 | 0.465 | 0.134 | 0.208 |
Best F1 = 0.358 at threshold 0.88. The looser threshold catches another 800 true matches (910 → 1,711) and only adds ~2,400 false positives — a much better trade-off than the tighter thresholds.
If you want maximum precision for a high-stakes merge (where every false merge is a problem), threshold 0.95 gives precision 0.465 with recall 0.134 — i.e., when it says match, it's right ~47% of the time, but it only finds ~13% of duplicates. Useful for surfacing candidates for human review.
If you want maximum recall for a candidate-generation step before another filter, threshold 0.88 gives recall 0.42 with F1 0.36.
There's no single "right" threshold; it depends on what you're using the output for.
What I Tried That Didn't Work
I want to document the dead ends because the post wouldn't be honest without them.
Multi-field weighted scoring (price + qty fingerprint)
I added the numeric fingerprint as additional matchkey fields to discriminate between similarly-named products at different price points:
matchkeys=[
MatchkeyConfig(
name="product_match",
type="weighted",
threshold=0.88,
fields=[
MatchkeyField(field="Description", scorer="embedding", weight=3.0,
transforms=["lowercase", "strip"]),
MatchkeyField(field="price_bucket", scorer="exact", weight=1.0),
MatchkeyField(field="qty_bucket", scorer="exact", weight=0.5),
],
),
],
| Metric | Embedding only | Multi-field (embed + price + qty) |
|---|---|---|
| F1 (GT v2) | 0.288 | 0.277 |
The multi-field config was worse. Why? Because the weighted scorer formula is sum(field_score × weight) / sum(weight), so a missing field actively drags the overall score down. For the pattern-rename pairs ('PARTY PIZZA DISH BLUE POLKADOT' GBP 0.68 vs 'PARTY PIZZA DISH BLUE RETROSPOT' GBP 0.97), the embedding score is high (~0.95) but the price buckets disagree (p_0_1 vs p_0_1 — wait, both are in 0-1; bad example). For the cases where prices differ across buckets, the score drops below threshold even though the strings clearly match.
The numeric fingerprint could help if the scorer was an OR over fields rather than a weighted average, or if I weighted Description so heavily that the price fields became tiebreakers only. But as configured, more fields hurt.
LLM iterative calibration (a second time)
I ran LLM calibration again with the multi-field config and the new GT. Same result — no change. The LLM can't filter false positives that the upstream scorer already accepted.
Tighter rerank bands
I tried rerank=True, rerank_band=0.05 with the cross-encoder/ms-marco-MiniLM-L-6-v2 reranker. It loaded the model in 50s but didn't move the F1 needle on this dataset because the rerank only re-scores a narrow band of pairs around the threshold, and the threshold-band pairs weren't where the errors lived.
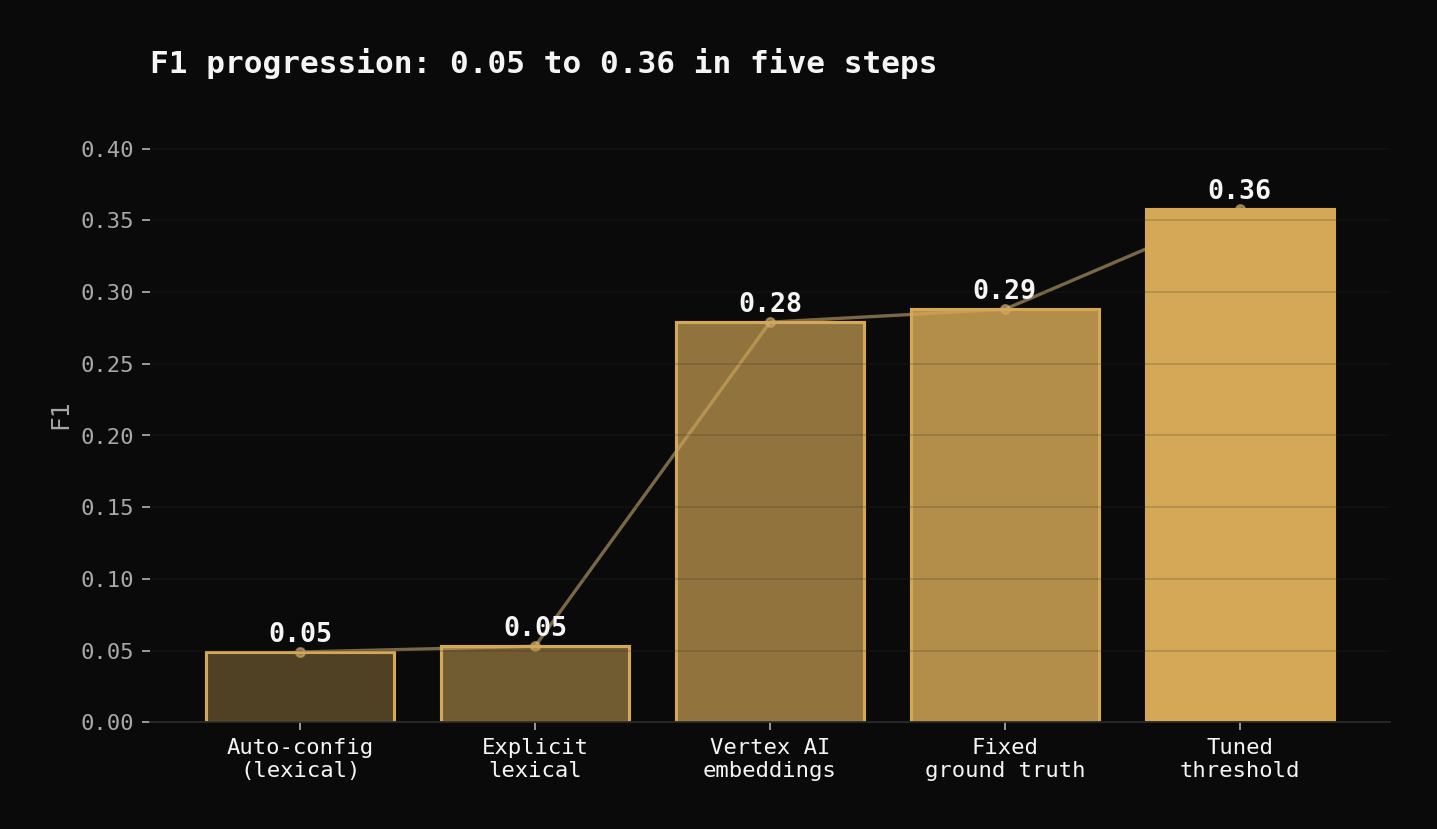
Why F1 = 0.36 Is the Ceiling (And Why That's Fine)
A 7× improvement to F1 = 0.36 sounds underwhelming until you look at the actual remaining "errors."
The remaining false positives
The 3,794 FPs at threshold 0.88 fall into three categories:
-
Real duplicates the GT v2 still misses. Despite normalizing StockCodes, the wholesaler sometimes assigned completely different StockCodes to the same physical product.
'JUMBO BAG RED RETROSPOT'exists under two unrelated StockCodes — it's the same bag, but the metric says they're different. -
Genuine semantic neighbors that aren't duplicates.
'PINK MUG'and'PINK CUP'have very high embedding similarity but are different SKUs. Hard to fix without explicit category information. -
Cross-pattern variants the GT v2 doesn't link.
'METAL SIGN,CUPCAKE SINGLE HOOK'appears under 6 different StockCodes — that's the wholesaler's own bookkeeping problem, not the matcher's.
The remaining false negatives
The 2,346 FNs at threshold 0.88 — pairs the matcher should have found but didn't:
[20685] 'DOORMAT RED RETROSPOT'
[20685] 'DOORMAT RED SPOT' ← same SKU, different name
[23028] 'DOORKNOB CRACKED GLAZE BLUE'
[23028] 'DRAWER KNOB CRACKLE GLAZE BLUE' ← rebrand: doorknob → drawer knob
[22829] 'BROCANTE SHELF WITH HOOKS'
[22829] 'SWEETHEART WIRE WALL TIDY' ← total rename, no shared tokens
[22777] 'GLASS BELL JAR LARGE'
[22777] 'GLASS CLOCHE LARGE' ← synonym substitution
These last two are illustrative: 'BROCANTE SHELF WITH HOOKS' and 'SWEETHEART WIRE WALL TIDY' share the same StockCode but zero string overlap and very low embedding similarity. No string-based or embedding-based matcher can recover these without external context like price history, co-purchase patterns, or human review.
This is the practical ceiling. To go higher you'd need:
- A second pass over price/quantity history to confirm rebrand candidates
- Co-occurrence with the same customer as a soft signal
- An LLM with the full product context (not just the descriptions, but order patterns, customer overlap, image data if available) to make judgment calls on the truly ambiguous pairs
GoldenMatch supports all of these, but at that point you're building a domain-specific dedup pipeline, not running a general-purpose configuration.
The Full Run Comparison
| # | Config | TP | FP | FN | Precision | Recall | F1 | Time |
|---|---|---|---|---|---|---|---|---|
| 1 | Zero-Config (GT v1) | 121 | 4,040 | 665 | 0.029 | 0.154 | 0.049 | 49.9s |
| 2 | Lexical (GT v1) | 449 | 15,653 | 337 | 0.028 | 0.571 | 0.053 | 1.3s |
| 3 | Lexical + LLM (GT v1) | 449 | 15,653 | 337 | 0.028 | 0.571 | 0.053 | 34.8s |
| 4 | Embedding t=0.92 (GT v1) | 427 | 1,847 | 359 | 0.188 | 0.543 | 0.279 | 271.7s |
| 5 | Embedding t=0.92 (GT v2) | 910 | 1,364 | 3,147 | 0.400 | 0.224 | 0.288 | 0s¹ |
| 6 | Embedding t=0.88 (GT v2) | 1,711 | 3,794 | 2,346 | 0.311 | 0.422 | 0.358 | 138.7s |
¹ The GT v2 re-evaluation reuses the cluster output from run 4 — no recompute needed, only the metric calculation changes.
The biggest single jump is run 4 → run 5: F1 stays similar but precision more than doubles without changing the matcher at all, just by fixing the metric. The biggest matcher-level improvement is lexical → embedding: 88% FP reduction and 5× F1 from switching the scorer.
Key Takeaways
- The metric is half the work. Fixing the StockCode normalization moved precision from 0.188 to 0.400 — a bigger improvement than any of the matcher changes. Before tuning the matcher, audit the ground truth.
- Lexical fuzzy matching is wrong for short product strings. Common tokens like
PINK,SET,METALcreate giant connected components. F1 = 0.05 across both zero-config and explicit lexical setups. - LLM scoring can't fix over-clustering. The GoldenMatch LLM scorer is designed to recover missed matches, not filter false positives. If your problem is too many FPs, the LLM is the wrong tool — you need better blocking, a tighter scorer, or human review.
- Embeddings are the right tool for short semantic strings. Switching to ANN blocking + embedding scorer dropped FPs by 88% and lifted F1 by 5×. Vertex AI
text-embedding-004handled the embedding via aGOLDENMATCH_GPU_MODE=vertexenvironment variable — no code change. - More fields can hurt. Adding numeric fingerprint columns to a weighted matchkey reduced F1 because the weighted average formula penalizes any field disagreement. Multi-field scoring works when fields agree; on rebrand-heavy data where prices change with the name, it's actively harmful.
- Threshold tuning is worth ~10 F1 points. The same embedding run swung from F1 = 0.21 (t=0.95) to F1 = 0.36 (t=0.88) just by changing one number. Always sweep.
- Pure dedup has a hard ceiling on this data. The remaining FNs include cases like
'BROCANTE SHELF WITH HOOKS'↔'SWEETHEART WIRE WALL TIDY'(same SKU, zero overlap). No text-based matcher can recover those without external signal.
Try It Yourself
Get the dataset:
pip install kagglehub
python -c "import kagglehub; print(kagglehub.dataset_download('mashlyn/online-retail-ii-uci'))"
Install the Golden Suite:
pip install goldenpipe goldenmatch goldencheck goldenflow
Run with Vertex AI embeddings (recommended for this task):
gcloud auth application-default login
export GOOGLE_CLOUD_PROJECT=your-project-id
export GOLDENMATCH_GPU_MODE=vertex
python dedup_products.py
Or run locally with pip install sentence-transformers and skip the GCP setup — all-MiniLM-L6-v2 will be used automatically.
Reproducibility Footer
- Source dataset: UCI Online Retail II via Kaggle (
mashlyn/online-retail-ii-uci, 14.5 MB) - Raw rows: 1,067,371 line items
- After filters (non-null Description, Price > 0, Quantity ≠ 0, non-cancellation): 1,041,670 rows
- Unique (StockCode, Description) combinations: 5,630
- Multi-description StockCodes: 648
- Ground truth pairs (raw StockCode): 786
- Ground truth pairs (normalized StockCode, trailing letter stripped): 4,057
- Best F1 achieved: 0.358 (single-field embedding, ANN blocking, threshold 0.88)
- Best precision: 0.465 at threshold 0.95
- Best recall: 0.716 at threshold 0.88 against GT v1 (a different operating point)
- Tools: goldenpipe 1.0.5, goldenmatch 1.4.4, goldencheck 1.0.2, goldenflow 0.1.0, polars 1.39
- LLM: OpenAI gpt-4o-mini (used in run 3 — found nothing to add)
- Embedding model: Vertex AI
text-embedding-004(or localall-MiniLM-L6-v2fallback) - Evaluation:
gm.evaluate_clusters(result.clusters, gt_pairs)against StockCode-derived ground truth, both raw and normalized - Hardware: Windows laptop, 32 GB RAM
- Data date: 2026-04-11
Related posts
From 51M Orders to Golden Customers: Full-Pipeline ER at Retail Scale
Running the full Golden Suite — GoldenCheck, GoldenFlow, GoldenMatch — on a Turkish retail CRM with 10.2M orders and 100K customers across 161 branches. 67 quality findings, 67K names normalized, 11,708 duplicate clusters discovered. European decimals, Turkish diacritics, and the false-positive pressure of common names on the same street.
2026-04-20
Reconciling 15 OSS Vulnerability Databases
Cross-database entity resolution across OSV, GHSA, PyPA, RustSec, and Go vulndb. 869k records, 608k canonical vulns, and one structural blind spot.
2026-04-10
Wallet Attribution at Scale: ER on 13M Blockchain Records
Running entity resolution across 10 public blockchain attribution datasets surfaces cross-jurisdictional sanctions and universal infrastructure patterns.
2026-04-09