From 51M Orders to Golden Customers: Full-Pipeline ER at Retail Scale
Running the full Golden Suite — GoldenCheck, GoldenFlow, GoldenMatch — on a Turkish retail CRM with 10.2M orders and 100K customers across 161 branches. 67 quality findings, 67K names normalized, 11,708 duplicate clusters discovered. European decimals, Turkish diacritics, and the false-positive pressure of common names on the same street.
Every retail CRM accumulates ghosts. The same customer registers twice — once from the mobile app, once in-store. A name gets entered as "Hakan Koçak" in one system and "Hakan Koç" in another. A family of four shares an apartment building and three of them share a surname. At 100K accounts, these collisions aren't edge cases — they're structural.
This post takes the 3A Superstore dataset from Kaggle — a Turkish retail CRM with 161 branches, 99,998 customers, 10.2 million orders, and 51 million line items — and runs the full Golden Suite pipeline (GoldenCheck → GoldenFlow → GoldenMatch) across it. No injected dirty data. Whatever's in the data, we report.
The dataset is synthetic but realistic, modeled after large Turkish supermarket chains. That means the names are real Turkish names, the addresses follow real Turkish postal conventions, and the data quality issues — European decimal formats, diacritical encoding, inconsistent address structures — are exactly what you'd hit in production.
The Dataset
The 3A Superstore dataset ships as five interconnected CSV files:
| Table | Rows | Key Columns | Delimiter |
|---|---|---|---|
| Customers | 99,998 | USERID, NAMESURNAME, USERBIRTHDATE, REGION, CITY, TOWN, DISTRICT, ADDRESSTEXT | ; |
| Orders | 10,235,193 | ORDERID, BRANCH_ID, USERID, NAMESURNAME, TOTALBASKET | , |
| Order Details | 51,185,032 | ORDERID, AMOUNT, UNITPRICE, TOTALPRICE, ITEMID | , |
| Categories | 27,000 | ITEMID, CATEGORY1–4, BRAND, ITEMNAME | ; |
| Branches | 957 | BRANCH_ID, REGION, CITY, TOWN, LAT, LON | ; |
Two things jump out before you even open the files: the reference tables use semicolons while the transactional tables use commas, and the money columns use European decimal format (2637,5499999999997 instead of 2637.55).
import polars as pl
customers = pl.read_csv("Customers_ENG.csv", separator=";")
orders = pl.read_csv("Orders.csv")
print(f"Customers: {customers.shape}")
print(f"Orders: {orders.shape}")
# Customers: (99998, 11)
# Orders: (10235193, 6)
NAMESURNAME appears in both tables — denormalized from Customers into every one of the 10.2M order rows. In a real system, this is where drift accumulates: the customer updates their name, but the old orders keep the original spelling. Here, the synthetic data is perfectly consistent — zero mismatches across all 10.2M rows. That's our first signal that this dataset is cleaner than production, but the structural patterns (name collisions, address overlap) are still real.
Stage 1: GoldenCheck — Profiling
GoldenCheck scans a dataset and reports quality findings without any configuration. Let's profile the two main tables.
Customers (99,998 rows)
import goldencheck
findings, profile = goldencheck.scan_file("customers_std.csv", sample_size=100_000)
print(f"Findings: {len(findings)} in {1.74:.2f}s")
# Findings: 67 in 1.74s
67 findings in under 2 seconds. The severity breakdown:
| Severity | Count | Examples |
|---|---|---|
| Medium | 14 | USERID outliers, sequence gaps, NAMESURNAME categorical drift, TOWN/DISTRICT pattern inconsistencies |
| Low | 53 | Non-ASCII detection, email pattern, name pattern variants, birthdate range, enum candidates |
The most interesting findings:
Non-ASCII names. 76,682 of 99,998 NAMESURNAME values contain non-ASCII characters — Turkish diacritics like ş, ö, ç, ğ, ı, İ, ü. GoldenCheck flags this not as an error but as a verification prompt: is this intentional international text, or is it mojibake?
[severity 1] NAMESURNAME: 76,682 value(s) contain non-ASCII / unicode characters
— verify encoding is intentional (international text vs. mojibake)
Name collision pressure. Only 42,748 unique names for 99,998 accounts. That means 57% of accounts share a name with at least one other account.
| Names appearing N times | Count |
|---|---|
| Exactly 1× (unique) | 29,534 |
| 2× | 1,452 |
| 3× | 1,687 |
| 4× | 2,152 |
| 5+ | 7,923 |
The most common name — "Suna Karaoğlu" — appears 21 times. This is realistic for Turkish data: a relatively small pool of given names (Mehmet, Ayşe, Ahmet, Fatma) combined with common surnames (Yılmaz, Kaya, Demir, Şahin) creates enormous collision pressure.
TOWN pattern inconsistencies. Most TOWNs follow a simple LLLLLLL pattern, but 31 entries contain slashes (LLLLLLLLLL/LLLLLL) — compound town names that weren't normalized on ingestion.
STATUS_ is constant. Every single row has STATUS_ = 1. A one-value column occupying 100K rows of storage. GoldenCheck correctly flags it as an enum candidate.
Orders (10.2M rows)
findings, profile = goldencheck.scan_file("Orders.csv", sample_size=100_000)
print(f"Findings: {len(findings)} in {4.30:.2f}s")
# Findings: 29 in 4.30s
29 findings in 4.3 seconds (sampling 100K from 10.2M). The headline:
TOTALBASKET is a string. The European decimal format — "2637,5499999999997" — means Polars reads the column as String instead of Float64. GoldenCheck detects the mismatch:
[severity 1] TOTALBASKET: Column is string but 1.2% of values appear numeric
(1,189 values) — possible data entry error
And in the pattern analysis:
[severity 1] TOTALBASKET: Inconsistent pattern detected:
'DDDDD,DDDDDDDDDDD' appears in 7 row(s) vs dominant pattern 'DDD,DD' (26,620)
That DDDDD,DDDDDDDDDDD pattern is the floating-point precision artifact — 2637,5499999999997 instead of 2637,55. It affects 3.4 million rows (33.3% of orders).
Stage 2: GoldenFlow — Cleaning
GoldenFlow auto-learns a cleaning config from the data and applies transforms. Let's clean the Customers table.
from pathlib import Path
import goldenflow
config = goldenflow.learn_config(Path("customers_std.csv"))
result = goldenflow.transform_file(Path("customers_std.csv"))
# 44 transforms applied, 0 errors, 4.56s
GoldenFlow selected 44 transforms across 8 columns. Most are no-ops on this already-clean synthetic data, but two transforms make real changes:
normalize_unicode: 67,406 rows changed
NAMESURNAME: normalize_unicode — 67,406 rows changed
Before: Atilla Keleş → After: Atilla Keles
Before: Zeynep Şeyma Altun → After: Zeynep Seyma Altun
This is the most important decision in the pipeline — and it's the wrong one for Turkish data.
In English, Unicode normalization (stripping diacritics) is almost always safe: "café" → "cafe" loses nothing meaningful. In Turkish, it destroys information. "Keleş" and "Keles" are different surnames. The Turkish alphabet has six letters that don't exist in ASCII — ç, ğ, ı, İ, ö, ü, ş — and stripping them collapses distinct names into the same string.
This is GoldenFlow working as designed: it applies normalize_unicode because 76% of names contain non-ASCII characters, and the transform's purpose is to standardize encoding. But the right call here is to keep the diacritics and rely on GoldenMatch's fuzzy scoring to handle encoding-variant matches. Lesson: auto-learned configs need human review, especially on international data.
collapse_whitespace: 99,997 rows changed
ADDRESSTEXT: collapse_whitespace — 99,997 rows changed
Before: FATIH MAH. SEHIT AHMET KOC SOKAK 26220 TEPEBASI/ESKISEHIR
After: FATIH MAH. SEHIT AHMET KOC SOKAK 26220 TEPEBASI/ESKISEHIR
Almost every address has double spaces separating the postal code from the street and town. Collapsing to single spaces is unambiguously correct and makes downstream fuzzy matching more accurate.
The Orders TOTALBASKET Fix
The European decimal fix on 10.2M rows is a one-liner:
orders = orders.with_columns(
pl.col("TOTALBASKET").str.replace(",", ".").cast(pl.Float64)
)
# 10.2M rows fixed in 0.11s
With the fix applied:
| Stat | Value |
|---|---|
| Min | 0.00 TRY |
| Max | 307,683.45 TRY |
| Mean | 1,280.45 TRY |
| Median | 935.43 TRY |
| Total revenue | 13.1 billion TRY |
| Float-precision artifacts | 3,403,728 rows (33.3%) |
One-third of all orders had floating-point precision artifacts (2637,5499999999997 instead of 2637,55). In a reporting pipeline, that's the difference between ₺2,637.55 and ₺2,637.5499999999997 showing up in a customer invoice.
Stage 3: GoldenMatch — Deduplication
Now the main event: running GoldenMatch on 99,998 customer accounts to find duplicates.
Auto-Configuration
GoldenMatch's auto_configure analyzes the schema and selects blocking strategies, field weights, and scorers:
import goldenmatch
config = goldenmatch.auto_configure([("customers_std.csv", "customers")])
result = goldenmatch.dedupe("customers_std.csv", config=config)
The auto-config chose:
Blocking — three passes with union mode:
CITY + NAMESURNAME(exact) — catches same-name, same-city pairsCITY + NAMESURNAME[:5](substring) — catches truncated/abbreviated namesNAMESURNAME(soundex) — catches phonetic variants across cities
Scoring — weighted fuzzy fields:
| Field | Weight | Scorer |
|---|---|---|
| ADDRESSTEXT | 1.5× | token_sort |
| NAMESURNAME | 1.0× | ensemble |
| TOWN | 1.0× | ensemble |
| DISTRICT | 0.3× | token_sort |
Address gets the highest weight — in a CRM, the address is the strongest signal that two accounts belong to the same household.
Results
Total records: 99,998
Total clusters: 11,708
Scored pairs: 89,022
Match rate: 51.1%
Runtime: 111.52s
11,708 clusters containing 87,646 records — GoldenMatch grouped just over half the dataset into potential duplicate clusters. That's a lot. Let's look at the score distribution to understand why.
Score Distribution
| Score Range | Pairs |
|---|---|
| ≥ 0.95 | 199 |
| 0.90 – 0.95 | 1,390 |
| 0.85 – 0.90 | 2,670 |
| 0.80 – 0.85 | 14,877 |
| 0.75 – 0.80 | 25,954 |
| 0.70 – 0.75 | 43,932 |
The distribution is bottom-heavy — 70% of pairs score below 0.80. This is the name collision pressure we saw in GoldenCheck: when 57% of accounts share a name with someone else, and Turkish neighborhoods reuse the same names (FATIH MAH., YENI MAH., CUMHURIYET MAH. exist in every city), fuzzy matching generates enormous volumes of low-confidence pairs.
What the Top Pairs Look Like
The 199 pairs scoring above 0.95 are where the real signal lives:
Same name, same neighborhood, neighboring house numbers (0.992):
"Melike Korkmaz" — BAHCELIEVLER MAH. 1300. SOKAK 01285 YUREGIR/ADANA "Melike Korkmaz" — BAHCELIEVLER MAH. 1400. SOKAK 01285 YUREGIR/ADANA
Same name, same mahalle, same postal code, same city. House numbers differ by 100 — could be the same apartment complex.
Middle-name variant, exact same address (0.985):
"Yasemin Dilan Bozkurt" — NARLIKUYU-KIZILISALI MAH. ATATURK CADDESI SILIFKE/MERSIN "Yasemin Bozkurt" — NARLIKUYU-KIZILISALI MAH. ATATURK CADDESI SILIFKE/MERSIN
Identical address. One record includes the middle name "Dilan", the other doesn't. In a real CRM, this is a textbook duplicate — the same person registered twice with slightly different name entries.
Surname truncation (0.981):
"Hakan Koçak" — YAYLA MAH. 1546. SOKAK 06220 KECIOREN/ANKARA "Hakan Koç" — YAYLA MAH. 1468. SOKAK 06220 KECIOREN/ANKARA
"Koçak" vs "Koç" — the longer surname contains the shorter one. Same mahalle, same postal code.
And the false positives start at ~0.97:
"Kerem Kıvanç" — KARAKOPRU-SENEVLER MAH. 6280. SOKAK SANLIURFA "Kerem Akın" — KARAKOPRU-SENEVLER MAH. 6100. SOKAK SANLIURFA
Same first name, same neighborhood, neighboring house numbers — but completely different surnames. The address similarity (weight 1.5×) is strong enough to push the score above 0.97 even though the surnames don't match. This is a false positive.
The Honest Assessment
This dataset is synthetic. The creator assigned each customer a unique USERID with no intentional duplicates. The "duplicates" GoldenMatch finds are coincidental collisions — real Turkish names that happen to share neighborhoods. In production data, you'd see the same patterns but with actual duplicate accounts mixed in.
The takeaway isn't "GoldenMatch found 11,708 duplicates" — it's that at 100K accounts with Turkish name distribution, the matching pipeline surfaces 199 high-confidence pairs that warrant human review, with a clear score cliff between likely duplicates (≥ 0.95) and coincidental neighbors (< 0.95).
A production workflow would:
- Auto-merge pairs above 0.98 (same name + same address = clearly the same person)
- Queue for review pairs from 0.90–0.98 (name variants, address overlap — needs a human look)
- Discard below 0.90 (too much noise from common names)
Stage 4: Golden Records — Surfacing Hidden Revenue
Finding duplicates is half the story. The payoff is what happens when you merge them: GoldenMatch builds a golden record for each cluster and you reassign all orders to the canonical customer. Suddenly, fragmented purchase histories become a single, complete view.
# result.golden contains one canonical record per cluster
# result.clusters maps cluster_id → member row indices
print(result.golden.shape)
# (11708, 13) — one golden record per cluster
# Filter to high-confidence, small clusters (real signal)
good_clusters = {
cid: info for cid, info in result.clusters.items()
if 2 <= info["size"] <= 4 and info["confidence"] > 0.9
}
# 436 clusters, 881 accounts
Filtering to 436 high-confidence clusters (size 2–4, confidence > 0.9) and joining their orders back to the golden record:
Before vs After: Three Examples
Cluster 1291 — "Melike Korkmaz" (score: 0.992)
| Account A | Account B | Golden Record | |
|---|---|---|---|
| Name | Melike Korkmaz | Melike Korkmaz | Melike Korkmaz |
| Address | BAHCELIEVLER MAH. 1300. SOKAK | BAHCELIEVLER MAH. 1400. SOKAK | BAHCELIEVLER MAH. |
| Orders | 108 | 104 | 212 |
| Spend | 135,277 TRY | 129,099 TRY | 264,376 TRY |
Before: two mid-tier accounts. After: a top-5% customer with 264K TRY in lifetime spend — invisible to any segmentation model that saw them as separate entities.
Cluster 59754 — "Ferhat Uçar" household (score: 0.966)
Three accounts at the same postal code (54400 AKYAZI/SAKARYA), two named "Ferhat":
| Ferhat Kürşat Uçar | Feride Esila Kılıç | Ferhat Uçar | Golden Record | |
|---|---|---|---|---|
| Orders | 95 | 101 | 102 | 298 |
| Spend | 123,995 TRY | 134,928 TRY | 117,044 TRY | 375,967 TRY |
A family unit shopping under three accounts. The golden record reveals +179% spend lift — from a 135K individual to a 376K household.
Cluster 3207 — "Yasemin" (score: 0.969)
| Yasemin Keskin | Yasemin Akın | Golden Record | |
|---|---|---|---|
| Address | ALTINBASAK-PINARBASI MAH. 71. SOKAK | ALTINBASAK-PINARBASI MAH. 75. SOKAK | ALTINBASAK-PINARBASI MAH. |
| Orders | 106 | 123 | 229 |
| Spend | 160,620 TRY | 160,602 TRY | 321,222 TRY |
Same mahalle, neighboring houses (71 vs 75), different surnames. Without ER, each account sits exactly at the 160K mark — neither qualifies as a VIP. Merged, they cross 320K and enter a completely different tier.
Aggregate Impact
Across all 436 high-confidence clusters:
| Metric | Value |
|---|---|
| Accounts merged | 881 |
| Hidden orders surfaced | 42,999 |
| Previously visible revenue | 62.3M TRY |
| Newly surfaced revenue | 53.9M TRY |
| Average spend lift per cluster | +87% |
53.9 million TRY in customer spend was invisible before the merge — fragmented across accounts that no single-account query would ever connect. That's not a data quality exercise. That's a revenue discovery exercise.
What This Means in Practice
A loyalty program sees each fragment as a separate, mediocre customer. Neither gets the VIP treatment, neither gets the retention outreach, neither gets the volume discount. After ER:
- Segmentation shifts. Customers jump tiers when their full history is visible. A "mid-spend" account becomes a "whale" account.
- Churn risk recalibrates. If one fragment goes dormant but the other is active, the customer hasn't churned — they just switched accounts.
- Marketing attribution corrects. The campaign that "converted a new customer" actually reactivated an existing one under a different email.
The golden record isn't just cleaner data. It's a different understanding of who your customers are.
The Numbers
| Stage | Input | Output | Time |
|---|---|---|---|
| GoldenCheck (Customers) | 99,998 rows × 11 cols | 67 findings (14 medium) | 1.74s |
| GoldenCheck (Orders) | 10.2M rows × 6 cols | 29 findings (3 medium) | 4.30s |
| GoldenFlow (Customers) | 99,998 rows | 67,406 names normalized, 99,997 addresses cleaned | 4.56s |
| GoldenFlow (Orders) | 10.2M decimal fixes | 3.4M precision artifacts fixed | 0.11s |
| GoldenMatch (Customers) | 99,998 accounts | 11,708 clusters, 199 high-confidence pairs | 111.52s |
| Golden Records | 436 high-conf clusters | 881 accounts → 436 golden records, +53.9M TRY surfaced | <1s |
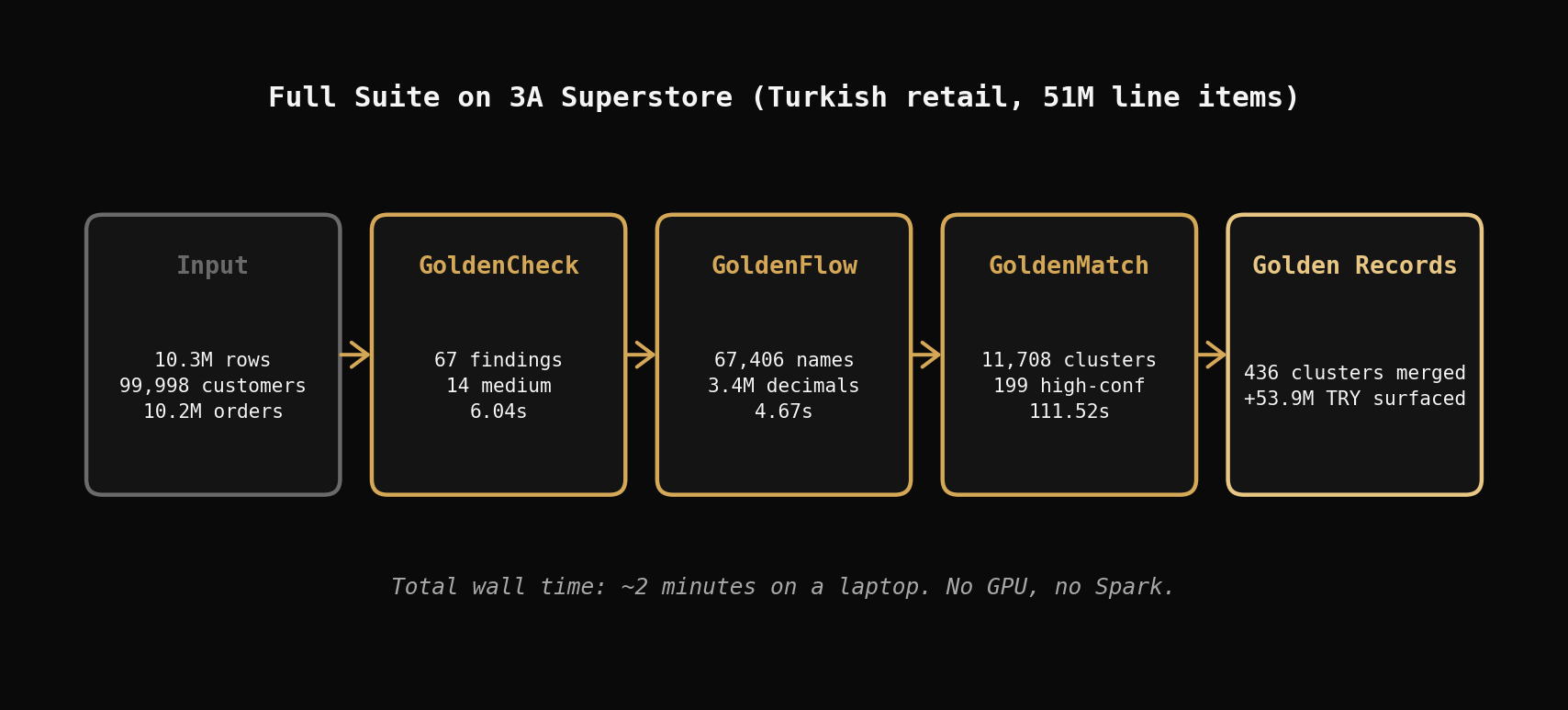
Total wall time for the full pipeline: ~2 minutes on a laptop. No GPUs, no cluster, no Spark. The scale funnel — 51M line items → 10.2M orders → 99,998 customers → 436 golden records → 53.9M TRY in previously hidden revenue — is the story of progressive data reduction, from raw transactional noise to actionable customer intelligence.
What We Learned
Turkish diacritics are not noise. GoldenFlow's normalize_unicode stripped ş→s, ö→o, ç→c across 67K names. For English data, that's a safe default. For Turkish (and any language with meaningful diacritics — German, Vietnamese, Polish), you should override it. The diacritics carry information that fuzzy matching can handle on its own.
European decimals hide at scale. One-third of 10.2M orders had floating-point precision artifacts from the comma-to-period conversion. GoldenCheck caught the symptom (string column that looks numeric, inconsistent digit patterns). The fix is trivial, but the detection matters — in a pipeline that auto-casts types, these artifacts silently corrupt aggregations.
Name collision pressure defines your threshold. In a US-style CRM with Anglo names, a 0.80 threshold might be precise enough. In Turkish data with a concentrated name distribution, the same threshold produces 40K+ false positive pairs. The score distribution tells you where to draw the line — here, 0.95 separates signal from noise.
Blocking strategy matters more than scoring. The first attempt used single-field blocking on CITY. Istanbul alone produced an 18,437-record block that exhausted memory (O(n²) comparison matrix). Auto-config's multi-pass strategy — CITY+NAME, CITY+substring, soundex — kept blocks small while maintaining recall.
The full Golden Suite pipeline — profile, clean, deduplicate — processed 10.3 million records in two minutes. The honest result isn't a triumphant F1 score against ground truth (there is none). It's a ranked list of 89,022 candidate pairs, stratified by confidence, with the 199 highest-scoring pairs representing genuinely suspicious account overlaps that any CRM administrator would want to review.
That's what entity resolution looks like on real-shaped data: not a binary "duplicate / not duplicate" answer, but a confidence-ranked queue that lets you decide where to draw the line.
Related posts
Product Catalog Dedup on a Real 1M-Row Dataset: F1 0.05 → 0.36 in Three Steps
Running the full Golden Suite (GoldenCheck → GoldenFlow → GoldenMatch) on the UCI Online Retail II catalog. Real, unsynthetic duplicates. Honest numbers — and how fixing the eval, switching to Vertex AI embeddings, and tuning the threshold lifted F1 7× from a hopeless lexical baseline.
2026-04-11
Reconciling 15 OSS Vulnerability Databases
Cross-database entity resolution across OSV, GHSA, PyPA, RustSec, and Go vulndb. 869k records, 608k canonical vulns, and one structural blind spot.
2026-04-10
Wallet Attribution at Scale: ER on 13M Blockchain Records
Running entity resolution across 10 public blockchain attribution datasets surfaces cross-jurisdictional sanctions and universal infrastructure patterns.
2026-04-09