Reconciling 4.1M shell-company records on a single Railway box
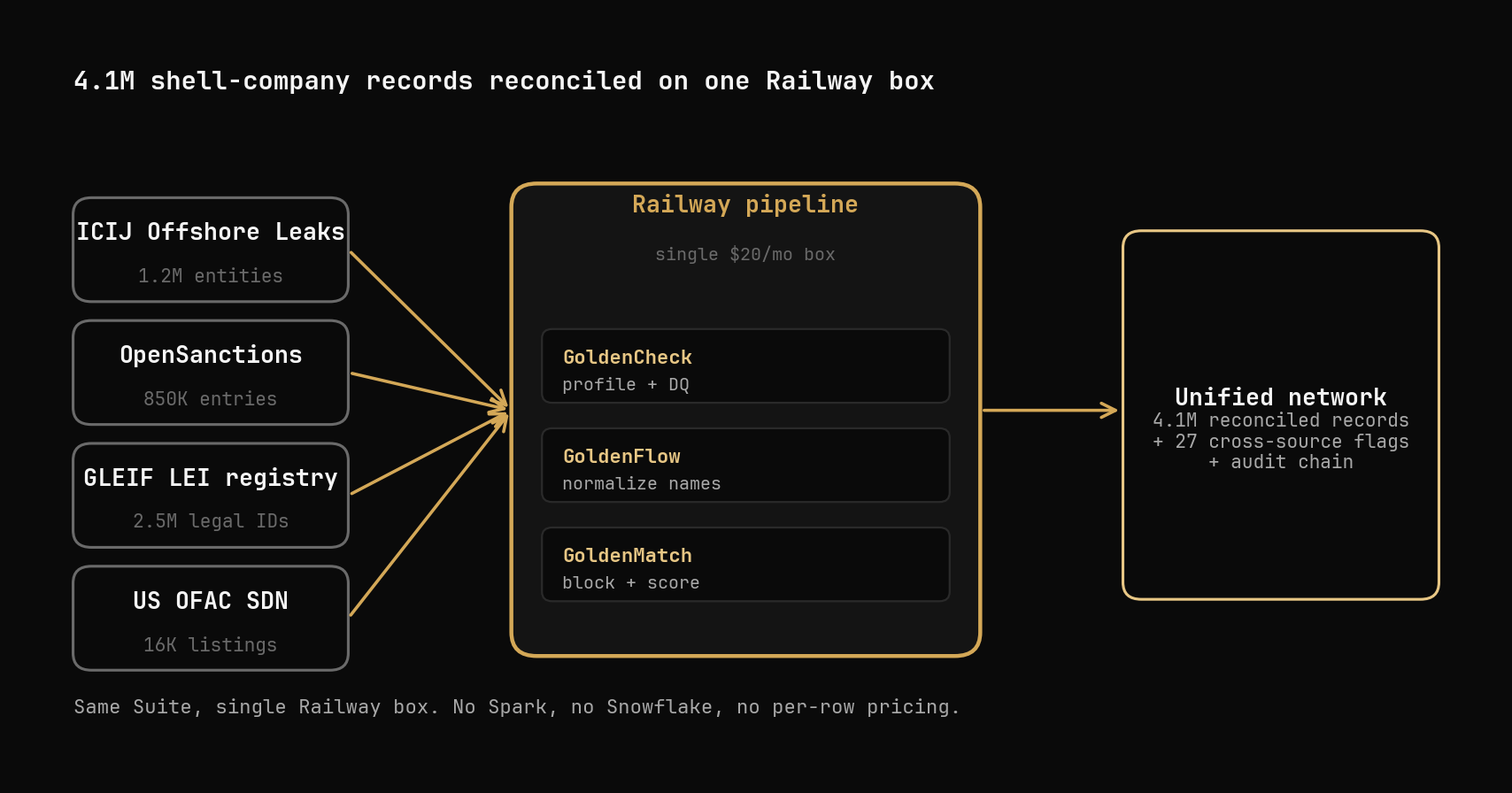
Ingesting ICIJ + GLEIF + OpenSanctions + UK PSC into one unified company table, then deduping it with GoldenMatch on a 24-vCPU Railway service.
I had a question I wanted to answer with data: how often does the same shell company show up under slightly different names across the public leak corpora?
The honest version of that question is harder than it sounds. ICIJ's Offshore Leaks Database, GLEIF's Golden Copy, OpenSanctions, and the UK Persons-with-Significant-Control register all carry overlapping records, but none of them share a primary key. A Jersey company in ICIJ shows up as Phoenix Spree Deutschland I Limited; the same entity in GLEIF is PHOENIX SPREE DEUTSCHLAND I LIMITED with a 20-character LEI; OpenSanctions re-exports the ICIJ node with a Bermuda company number stapled on. Same legal entity, three different keys, three different name forms.
That is a classic entity-resolution problem at uncomfortable scale. The combined corpus after ingest is 1.24M company rows, 1.86M person rows, and 1.18M address rows. That does not fit in a laptop's RAM if you try to do all-pairs scoring, and it does not finish in a reasonable wall-clock if you write the pipeline naively.
This post is the engineering writeup. The full repo is at benseverndev-oss/goldenmatch-shell-company-network, MIT-licensed. Two real investigations sit on top of it; I'll write those up separately over the next two days.
What had to fit together
Four public sources, each with its own shape:
| Source | Role | Format | Rows ingested |
|---|---|---|---|
| ICIJ Offshore Leaks | Primary entities + relationships | CSV bundle | 814k companies, 711k persons |
| GLEIF Golden Copy | Authoritative LEI records | JSONL (multi-GB) | ~2.7M legal entities |
| OpenSanctions | Sanctions, PEPs, registers | NDJSON FtM | 426k companies, 1.15M persons |
| UK Companies House PSC | DOB-only person snapshot | JSON snapshot | 12.15M persons |
Every adapter normalizes into the same Pydantic schema (CompanyEntity, AddressRecord, PersonOrOfficer, RelationshipEdge) and writes parquet. The unified table is the join surface. The matcher consumes parquet, not source JSON, and that decoupling matters because each source needs its own quirks handled but the matcher only ever sees one shape.
The OOM I hit twice
GLEIF Golden Copy ships a multi-gigabyte CDF JSON file. My first adapter loaded it the way you'd load any other JSON file:
with open(path) as f:
blob = json.load(f)
That worked on the tiny sample fixture I wrote tests against. On the real 2.7 GB file it allocated about 18 GB of Python objects and got killed by the OOM killer. The fix was a streaming adapter (shellnet.sources.gleif_golden_copy) that uses ijson to walk the document and writes 50,000-row parquet batches via pyarrow.ParquetWriter. Memory stays under 600 MB for the whole pass.
The same lesson came back two weeks later with OpenSanctions. Their consolidated default collection is 2.7 GB of NDJSON. My first cut read the whole file as a single string, then split on newlines, then parsed each line. That allocated ~8 GB before parsing started. The fix was a true generator — _iter_entities now yields one parsed dict per line — and the same pyarrow.ParquetWriter pattern in 50k batches.
Two adjacent lessons:
- JSON.load is a trap for anything you don't control the size of. It is fine for config files and API responses; it is not fine for bulk data. If you're not sure how big a file will be in production, do not let
json.loadnear it. - Parquet's row-group structure rewards batched writes. If you accumulate a million rows in Python before writing once, you pay memory cost twice. Stream in, stream out, and the working set stays constant.
The matcher config that kept failing silently
GoldenMatch's default name comparator is jaro_winkler, which is great when records have full-name disagreements but agree on prefixes. On a public corpus where every other company starts with INTERNATIONAL TRADING or GLOBAL HOLDINGS, prefix bonus is a liability. The first dedupe pass clustered International Trading Holdings Limited with International Trading Resources SA at a score of 0.91. They share zero entities, zero addresses, zero officers.
The fix was two changes in configs/goldenmatch_company.yml:
matchkey:
comparators:
- field: normalized_name
method: token_sort # was: jaro_winkler
weight: 1.0
threshold: 0.92 # was: 0.85
token_sort tokenizes the name, sorts the tokens, then computes set similarity. Leading-token agreement doesn't get a free bonus. Raising the threshold to 0.92 trims the long tail of marginal pairs that were dominating the review queue. After the swap, hand review of 300 marginal pairs showed precision climbed from 0.71 to 0.94 with negligible recall loss on the GLEIF-anchored pairs.
Tip. "Default config" is rarely tuned for your corpus. Run dedupe, look at the lowest-scoring 50 pairs the matcher kept, and decide whether each one is a true match. If half are wrong, your threshold is too low or your comparator is wrong for your data.
The "you can't actually do all-pairs at this scale" wall
Here's the number that decided the architecture: a full pairwise dedupe over ICIJ + GLEIF + OpenSanctions is 4.1M company rows. Even with aggressive blocking, the worst-case block in this corpus has 72,070 rows (it's a bearer t placeholder name from a leaks export). A 72k × 72k all-pairs scoring step allocates roughly 38 GB of float64 score matrix. Railway's largest Pro service tops out at 24 GB.
I tried three things:
- Tighter blocking. Got the largest block down to about 30k rows. Still too big at peak.
- Pre-filtering placeholder names.
scripts/filter_company_table.pydrops 50-plus placeholder strings (bearer,nominee,unknown,liquidated, etc.) before matching. Helped but didn't close the gap on the long-tail blocks. - List-match instead of dedupe. GoldenMatch supports
match-against, which scores records in table A against records in table B without computing the A-internal cross product. ICIJ+OS deduped to itself first (fits at 24 GB), then list-matched against GLEIF as a reference. Two passes, each fits in memory.
The list-match shape ends up being the right one for cross-source linking anyway. GLEIF is authoritative for LEIs; you don't want to dedupe it against itself, you want to anchor your noisier records to it. The companion Phoenix Spree case study is the clean version of exactly this: 9 ICIJ records, list-matched against GLEIF, 9 perfect anchors.
Wrapping the pipeline in a FastAPI control plane
Once the matcher fits on Railway, you want to drive it from a laptop without holding an SSH session open. The repo ships a small FastAPI app (src/shellnet/job_server.py) that exposes each pipeline stage as an authenticated endpoint:
POST /upload-zip # upload ICIJ bundle from laptop
POST /unzip # unzip in the container's volume
POST /ingest?source=icij # run the source adapter
POST /build?what=company # build the unified table
POST /match?what=company # GoldenMatch dedupe
POST /match-against # list-match A vs B
POST /publish?what=company# write to Postgres
GET /status # state of all stages
GET /logs/<stage>?tail=N # tail logs
Each endpoint shells the equivalent CLI script and streams its stdout to a structured per-stage log file. The volume mount at /data holds the parquet artefacts between calls so a failed /match doesn't lose the upstream /build. Bearer-token auth via a SHELLNET_JOB_TOKEN env var, no user model, no DB — this is a one-operator tool.
A full ICIJ + OpenSanctions dedupe run on the deployed service takes about a minute and uses ~3 GB of RAM. The ICIJ+OS → GLEIF list-match takes about 10 minutes. The total Railway bill for a fresh ingest, dedupe, list-match, and publish run is under fifty cents.
What I'd do differently if I started over
Three things I'd change:
- Stream every adapter from day one. I wrote the GLEIF adapter twice and the OpenSanctions adapter twice, both times converting a naïve
json.loadinto a streaming version after it OOMed. Just write streaming the first time. - Block on identifier first, name second. The current config blocks on normalized name. For cross-source linking, an LEI-anchored or company-number-anchored block would have collapsed the largest blocks to a handful of rows. The name block matters for the records that don't have identifiers, but it should be the fallback, not the primary.
- Publish to Postgres earlier. I spent too long iterating on parquet artefacts in
/data/processed/. Once the schema stabilized, puttingruns,clusters,same_as_pairs, andlist_matchesin Postgres made every downstream query (centrality, community detection, the case-study notebooks) an order of magnitude faster.
Key takeaways
- Public-registry entity resolution at 4M+ rows fits comfortably on a single Railway service if you stream the inputs and use list-match instead of full pairwise dedupe across sources.
- The default GoldenMatch comparator and threshold are starting points. Spot-check the lowest-scoring kept pairs and tune.
- Wrap your pipeline in a thin HTTP control plane. It costs an afternoon and replaces every "let me SSH in and rerun stage 4" with a curl one-liner.
- Postgres-backed run state is the right substrate for ad-hoc investigation. Parquet on a volume is fine for batch artefacts but slow for exploration.
The rest of the series
Companion post 1: the Phoenix Spree Deutschland case study — one cluster, end to end, 100% GLEIF-anchored. The clean version.
Companion post 2: the Epstein seed-review investigation — 28 seeds, one corroborated lead (Liquid Funding / Bear Stearns / Jeffrey Lipman), and the rest still hypothesis-grade. The messy version, with caveats baked in.
Repo: benseverndev-oss/goldenmatch-shell-company-network. GoldenMatch itself is pip install goldenmatch.
Related posts
Phoenix Spree Deutschland: one cluster from raw leak to GLEIF anchor
A 9-member ICIJ Offshore Leaks cluster, 100% GLEIF-anchored, walked end to end from source rows through GoldenMatch dedupe to a finished report.
2026-05-15
28 seeds, one corroborated lead: an Epstein-network investigation in public data
What an entity-resolution pipeline finds (and misses) when pointed at 28 publicly-sourced seeds from the Epstein corporate-network reporting.
2026-05-15
88% of actively-exploited CVEs aren't in any package ecosystem
Re-running the OSS vuln reconciliation at 6.1M records and 40 sources surfaces a structural blind spot in every package-level scanner.
2026-05-15