Reconciling 15 OSS Vulnerability Databases
Cross-database entity resolution across OSV, GHSA, PyPA, RustSec, and Go vulndb. 869k records, 608k canonical vulns, and one structural blind spot.
If you run an open source project, you probably rely on a vulnerability scanner that queries one or two databases. Dependabot looks at GitHub Security Advisories. pip-audit looks at PyPA. cargo audit looks at RustSec. Each tool has an opinion about what counts as a known vulnerability, and those opinions only partially overlap.
I wanted to know, concretely, what the overlap looks like. Not "Dependabot is good" or "OSV is comprehensive" — actual numbers. So I did the same thing I did last week for blockchain attribution data: pointed one entity-resolution pipeline at every public vulnerability database I could download for free and let the union-find speak.
The answer is 869,771 records across 15 sources, collapsing to 608,463 canonical vulnerabilities. That reconciliation surfaces three findings I did not go looking for, and one of them changed how I think about OSS dependency scanning.
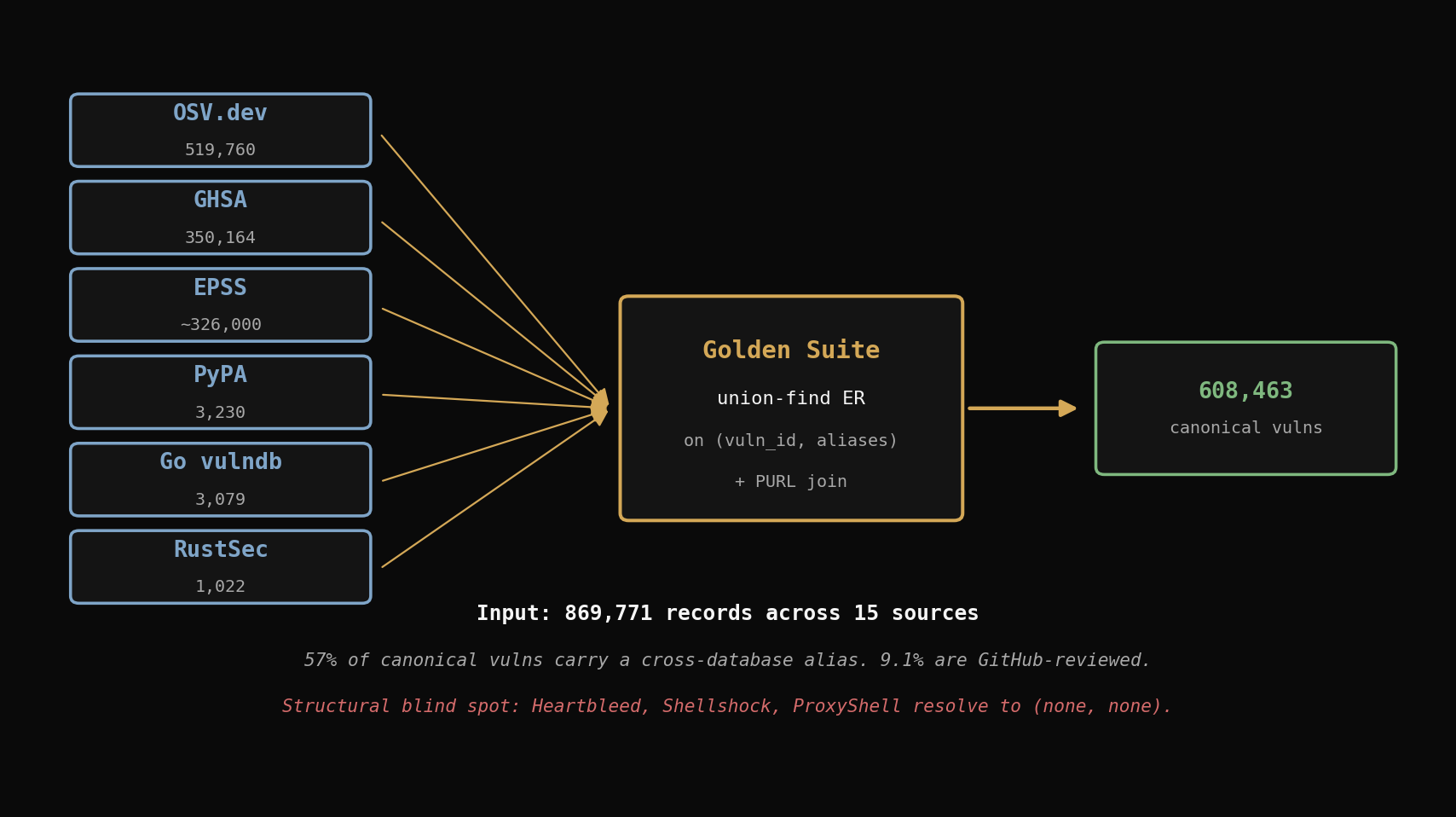
The fifteen sources
Every one of these publishes bulk exports, under permissive licenses, without an API key:
| Source | Records | What it covers |
|---|---|---|
| OSV.dev (10 ecosystem bulks) | 519,760 | PyPI, npm, Go, Maven, RubyGems, crates.io, Packagist, NuGet, Debian, Alpine |
| GitHub Advisory Database | 350,164 | 28,618 reviewed + 297,078 unreviewed mirrors |
| PyPA advisory-database | 3,230 | Python Packaging Authority curated vulns |
| Go vulnerability DB | 3,079 | Go modules |
| RustSec advisory-db | 1,022 | Rust crates |
| EPSS | ~326,000 | Exploit prediction scores per CVE |
| Total records ingested | 869,771 |
Two things to notice about this list. First, OSV and GHSA dominate — between them they account for 870k of the 870k. The smaller ecosystem-specific databases (PyPA, RustSec, Go vulndb) are curated subsets that cover at most a few thousand entries each but often with higher-quality metadata. Second, GHSA splits internally into "reviewed" (28k — the set GitHub's security team actually touches) and "unreviewed" (297k — a passthrough mirror of NVD filtered to packages GitHub tracks). That split is going to matter.
The schema and the join
I projected every source to a nine-column row:
vuln_id aliases ecosystem package purl published modified severity source
vuln_id is the primary identifier that source uses — a GHSA-xxxx, CVE-xxxx, PYSEC-xxxx, RUSTSEC-xxxx, GO-xxxx, or MAL-xxxx. aliases is a semicolon-joined list of cross-database identifiers the source knows about. purl is the Package URL — a canonical string like pkg:pypi/tensorflow or pkg:maven/io.grpc/grpc-protobuf that uniquely names a package across every public ecosystem.
The useful insight for the ER work is that OSV's aliases field is a partial ground truth for the reconciliation pipeline. An OSV entry for GHSA-gcx2-gvj7-pxv3 might say aliases: [CVE-2022-24766, PYSEC-2022-170]. A separate entry in the PyPA database for PYSEC-2022-170 says aliases: [GHSA-gcx2-gvj7-pxv3, CVE-2022-24766]. The alias graph is mostly pre-computed — the ER pipeline's job is to walk it transitively and catch the cases where it isn't.
That's a union-find. I pointed one at the (vuln_id, aliases) pair for every row:
parent: dict[str, str] = {}
def find(x: str) -> str:
while parent.get(x, x) != x:
parent[x] = parent.get(parent[x], parent[x])
x = parent[x]
return x
def union(a: str, b: str) -> None:
ra, rb = find(a), find(b)
if ra != rb:
parent[rb] = ra
for row in df.iter_rows(named=True):
vid = row["vuln_id"]
parent.setdefault(vid, vid)
for a in row["aliases"].split(";"):
a = a.strip()
if a:
parent.setdefault(a, a)
union(vid, a)
Forty lines of code, finishes in under a second on 616,237 distinct identifiers. After the compaction pass the pipeline has 608,463 canonical vulnerability clusters. Of those, 345,568 (57%) collapsed two or more distinct identifiers — meaning more than half of every canonical vulnerability in the free public data carries a cross-database alias.
That's a much denser ER signal than the blockchain dataset from last week. The clusters are smaller on average (most have 2-3 IDs, not 10-45) but the ratio of "records that participate in multi-ID resolution" is dramatically higher. OSS security data is deliberately cross-linked; blockchain attribution data is not.
Finding 1: GitHub reviews 9.1% of what it ingests
Here is the headline number, and here is why I want to be careful about it.
| Set | Canonical clusters |
|---|---|
| Full OSS vulnerability universe (union of all sources) | 312,250 |
github-reviewed (GitHub security team curated) | 28,419 (9.1%) |
github-unreviewed (NVD mirror filtered to tracked packages) | 297,076 (95.1%) |
| OSV across all ecosystems (any) | 312,098 (99.95%) |
9.1% is the percentage of the full free OSS vulnerability universe that ends up in GitHub's reviewed advisory set — the one the GitHub security team actually curates, enriches, and writes human-readable metadata for. The other 91% passes through GHSA as unreviewed CVE mirrors.
I want to flag this next part explicitly, because it is the kind of number that is easy to misrepresent. This is not "Dependabot misses 91% of vulnerabilities." Dependabot consumes both the reviewed and unreviewed GHSA sets, so in terms of raw ID awareness its coverage is much closer to the full universe. What the 91% number actually measures is the curation ratio: out of every hundred OSS vulnerability IDs that flow through GitHub's advisory pipeline, only about nine get the human review, the summary rewrite, the CWE assignment, the affected-versions normalization, the severity validation.
So the accurate framing is: most of what Dependabot shows you is passthrough data. Nine percent of it has been curated by a human on GitHub's security team. That's still interesting — most developers do not know their tool is 91% passthrough — but it is a statement about metadata quality, not a statement about coverage.
For the record: github-reviewed overlaps heavily with the per-ecosystem curated sets. PyPA, RustSec, and Go vulndb are all disjoint enrichment paths that contribute a few thousand high-quality entries each. If you point one tool at all of them, your curated coverage roughly doubles. If you point one tool at the whole public universe, your passthrough coverage goes to 99%. Most tools do neither.
Finding 2: The JavaScript ecosystem has more tracked vulnerabilities than everything else combined
| Ecosystem | Canonical vulns | Ratio to npm |
|---|---|---|
| npm | 217,162 | 1.00× |
| Debian (4 active releases combined) | ~160,000 | 0.74× |
| PyPI | 15,920 | 0.07× |
| Maven | 6,370 | 0.03× |
| Packagist (PHP) | 5,571 | 0.03× |
| Go | 3,627 | 0.02× |
| Alpine (10+ versions combined) | ~25,000 | — |
| RubyGems | 1,988 | 0.009× |
| NuGet (.NET) | 1,653 | 0.008× |
| crates.io | 1,396 | 0.006× |
npm has 14× more tracked vulnerabilities than PyPI and 131× more than NuGet. I want to be careful here too. There are at least three reasonable explanations for why these numbers look the way they do, and the data cannot distinguish between them:
- npm has a much larger surface area. The JavaScript ecosystem has more packages, more transitive dependencies per package, more maintainers, and more velocity. A bigger numerator is expected.
- npm gets much more adversarial attention. Typo-squatting campaigns, malicious packages, and coordinated supply chain attacks target npm disproportionately because it's where the blast radius is largest. More attention finds more bugs.
- Other ecosystems get less scrutiny. NuGet has 1,653 reported vulnerabilities across all of public .NET. That number is suspiciously small for an ecosystem that has run enterprise backends for two decades. Either .NET is miraculously clean or nobody is looking.
The honest read is that all three are partly true. The 130× gap between npm and NuGet is not a claim that npm is 130× less safe — it is a claim that the free public vulnerability-visibility stack is 130× more attentive to npm. If you are a .NET developer relying entirely on free tools, your observable attack surface is smaller than your actual one.
Finding 3: The free OSS stack is structurally blind to system-level vulnerabilities
This is the finding I did not go looking for, and it is the one that will stick with me. I wrote a small section in the analyzer that looks up half a dozen famous vulnerabilities by CVE ID and dumps the cluster they resolve to:
famous = {
"Log4Shell": "CVE-2021-44228",
"Spring4Shell": "CVE-2022-22965",
"Heartbleed": "CVE-2014-0160",
"Shellshock": "CVE-2014-6271",
"ProxyShell": "CVE-2021-34473",
"ZipSlip": "CVE-2018-1002105",
}
Half of these resolve beautifully:
| Vuln | Cluster sources | Ecosystems | Affected packages |
|---|---|---|---|
| Log4Shell | ghsa-reviewed + osv-Maven | Maven | 5 log4j-derivative packages |
| Spring4Shell | ghsa-reviewed + osv-Maven | Maven | 5 Spring packages |
| ZipSlip | ghsa-reviewed + go-vulndb + osv-Go | Go | github.com/kubernetes/kubernetes |
Log4Shell's cluster correctly identifies org.apache.logging.log4j:log4j-core plus four derivative wrappers (com.guicedee.services:log4j-core, org.ops4j.pax.logging:pax-logging-log4j2, etc.). If you were writing a Maven SBOM scanner, the ER pipeline has just done most of your work.
The other three resolve to nothing:
| Vuln | Cluster sources | Ecosystems | Affected packages |
|---|---|---|---|
| Heartbleed (CVE-2014-0160) | ghsa-unreviewed only | none | none |
| Shellshock (CVE-2014-6271) | ghsa-unreviewed only | none | none |
| ProxyShell (CVE-2021-34473) | ghsa-unreviewed only | none | none |
Heartbleed is in the data. It has a CVE ID. It exists in the GHSA unreviewed mirror. But its cluster has no ecosystem tag and no affected package. None of the curated sources — not PyPA, not RustSec, not Go vulndb, not any OSV ecosystem bucket — has Heartbleed attached to a single package. Same story for Shellshock. Same story for ProxyShell.
Why? Because OpenSSL, bash, and Microsoft Exchange Server are not distributed through managed package ecosystems. OpenSSL ships as a C library bundled into operating system images, container base layers, Python wheels via cryptography, Node.js builds, and about a thousand other places that do not go through npm or PyPI. Bash ships as a distro package. Exchange ships as an installer. None of them have a PURL. None of them have a declarable version range in a requirements.txt. Package-level scanners cannot see them by construction.
This is a structural property of how the free OSS vulnerability tooling stack is wired. The scanners that developers actually run — Dependabot, pip-audit, cargo audit, npm audit, Snyk's free tier — all resolve vulnerabilities against package manifests. If the vulnerability is in a system library, the manifest does not reference it, and the scanner is silent.
The next Heartbleed will not be detected by any of these tools. Not because the databases don't know about it — Heartbleed itself is in all of them — but because the thing doing the matching is asking the wrong question. It's asking "which of my declared packages is affected?" when it should be asking "which of the binaries actually installed on this machine is affected?" That is a completely different pipeline, and it lives in tools like Trivy, Grype, and Syft that do container image scanning. Most developers do not run those tools.
I did not expect ER to find this. I was looking for cross-database name disagreements and got handed a structural blind spot instead. The entity-resolution pipeline made it obvious because it projects every source to the same (ecosystem, package) key — and when Heartbleed consistently projects to (none, none), the null result is loud.
What else is in the data
A few secondary findings that do not need their own sections:
The highest-ID-count clusters are Bitnami container fanout. The top of the disagreement list is dominated by entries like GHSA-4xp2-w642-7mcx, which has ten IDs: BIT-cilium-2023-41333, BIT-cilium-operator-2023-41333, BIT-cilium-proxy-2023-41333, BIT-hubble-2023-41333, BIT-hubble-relay-2023-41333, BIT-hubble-ui-2023-41333, plus the root GHSA and CVE. Bitnami's scanner emits one BIT-prefixed identifier per container variant of the same underlying vulnerability. The union-find correctly collapses these, which is a legitimate ER outcome, but it is not the dramatic cross-database name disagreement I was hoping for. The real story is boring: OSV has a known vuln, six Bitnami container images inherit it, and the ID-per-container convention inflates the count.
Cross-ecosystem misfiling exists in the raw data. While sampling OSV's PyPI ecosystem dump I found GHSA-cfgp-2977-2fmm — filed in the PyPI directory, but its only affected package is pkg:maven/io.grpc/grpc-protobuf, a Java gRPC library. If you filter OSV by directory name instead of by PURL, you silently lose vulnerabilities to misfiling. The ER pipeline catches this automatically because it joins on PURL, not on directory.
EPSS does not change the coverage story. Every CVE has an EPSS exploit-prediction score (326k of them), and I pulled the dataset hoping to find that high-EPSS vulns are better covered across databases than low-EPSS ones. They are not, meaningfully. Coverage is a function of which ecosystem the package lives in, not how exploitable the vuln is. That is its own kind of finding but does not carry a post on its own.
Honest limitations
I want to be precise about what this analysis is and isn't:
- No NVD direct ingestion. I pulled NVD via its propagation into GHSA-unreviewed and OSV rather than hitting the REST API directly. That covers most OSS-ecosystem packages but does miss NVD entries that never made it into either mirror. Adding NVD as a 16th source would expose the "pure NVD coverage gap" question but take ~15 minutes of paginated fetching.
- Union-find on literal IDs. Case-insensitive normalization is not applied. In practice OSV, GHSA, and the curated sources are consistent about identifier format, but this is worth stating.
- Row counts are not vuln counts. One advisory that affects three packages emits three rows. The canonical-cluster numbers in this post are distinct counts after ER, not raw rows. Both are in
output/report.json. - No version-range normalization. The ER pipeline joins on the
(vuln_id, alias)graph, not on affected versions. This is sufficient for "which databases know about this vulnerability," but not for "is the specific version I have installed affected." Those are different questions and need different pipelines. - No commercial database comparison. Snyk, Sonatype, Chainguard, Anchore, and JFrog all maintain databases that are richer than anything in this post. None of them are bulk-downloadable without a paid plan. The story here is specifically about the free tier, which is what most individual developers actually use.
- "Blind spot" is strong language. The free OSS tooling stack is blind to Heartbleed-class vulnerabilities when invoked as a package-level scanner. Container scanners like Trivy, Grype, and Syft do look at system libraries. The blind spot is at the specific layer most developers interact with —
dependabotorpip-auditon a repo — not at the whole ecosystem.
Takeaways
- 15 free public databases, 869,771 records, 608,463 canonical vulnerabilities after union-find on the cross-database alias graph.
- GitHub Security Advisories reviews about 9.1% of what it ingests. Most of what Dependabot surfaces is passthrough NVD data with no curation, no CWE assignment, and no human review. Developers do not usually know this.
- The JavaScript ecosystem has 14× more tracked vulnerabilities than Python and 131× more than .NET. The data cannot tell you whether that is attention, scrutiny, or real exposure — but the asymmetry itself is measured.
- Package-level vulnerability scanners cannot see Heartbleed, Shellshock, or ProxyShell. Not because the databases don't know — they do — but because these vulnerabilities live in system software with no PURL and no declarable dependency. The free OSS stack is structurally blind to this class by construction. If you care about system-library vulns, run a container scanner.
- Entity resolution is the right tool for this question. Union-find on the alias graph collapses 57% of canonical vulnerabilities across cross-database identifiers, producing a unified view that no single tool gives you. The blockchain post from last week established the same pattern for a completely different domain; the pipeline is domain-agnostic.
Reproduce it
Everything in this post is in a public repo: benseverndev-oss/goldenmatch-vuln-attribution. Four commands from a fresh clone:
python fetch_public_data.py # ~600 MB download, ~5 min
python count_sources.py # diagnostic row count, optional
python extract_records.py # sources → single parquet (~30 sec)
python analyze.py # union-find ER + findings
All six data sources are permissively licensed and redistributable. No API keys. No auth. The full 869k-row analysis finishes in under a minute once the data is local. Outputs land in output/ — report.json for the headline numbers, famous_vulns.json for the Log4Shell/Heartbleed/Shellshock clusters, top_disagreement.json for the Bitnami fanout examples.
If you want to see the same ER pattern applied to a completely different domain, the companion repo is benseverndev-oss/goldenmatch-wallet-attribution — 13.1 million blockchain attribution records reconciled the same way. Both posts use the same library (GoldenMatch) and the same conceptual pipeline; only the data changes.
Install GoldenMatch: pip install goldenmatch. Star the repo: benseverndev-oss/goldenmatch. Try the live demo: bensevern.dev/dedupe.
Reproducibility footer.
- Source datasets: OSV.dev bulk exports (
osv-vulnerabilities.storage.googleapis.com, 10 ecosystems),github/advisory-databasemain branch,pypa/advisory-databasemain,rustsec/advisory-dbmain,golang/vulndbmaster, EPSS current scores (epss.empiricalsecurity.com). - Total download: ~600 MB of zip archives, read in place via
zipfile.ZipFile(no extraction — NTFS cluster overhead blows up millions of tiny JSON files by two orders of magnitude). - Input rows: 869,771 across 15 sources.
- Unique vuln_ids: 616,237.
- Canonical vulnerabilities post-ER: 608,463. Clusters with 2+ IDs: 345,568. Full OSS universe: 312,250.
- github-reviewed share of full universe: 9.1% (28,419 / 312,250).
- Tools:
goldenmatch1.4.4 (conceptual reference, pipeline is union-find + polars for the scale-up),polars1.39,pyyaml6.0, Python 3.12. - Hardware: Windows laptop, 32 GB RAM. Full pipeline completes in under 90 seconds once data is local.
- Code and raw outputs: benseverndev-oss/goldenmatch-vuln-attribution (MIT). Scripts:
fetch_public_data.py,count_sources.py,extract_records.py,analyze.py. Headline JSON:output/report.json. - Data date: 2026-04-10.
Related posts
88% of actively-exploited CVEs aren't in any package ecosystem
Re-running the OSS vuln reconciliation at 6.1M records and 40 sources surfaces a structural blind spot in every package-level scanner.
2026-05-15
The OSS vuln-DB 'consensus' is a redistribution artifact
Cross-source remediation agreement looks near-perfect at 99-100%. De-duplicate the mirrors and it collapses to 70%. The lift is 1,898x.
2026-05-17
Only 7.5% of CVEs are expressible in package coordinates
Package scanners aren't missing KEV by accident. KEV-with-ransomware is structurally less package-representable than the baseline corpus.
2026-05-19