The OSS vuln-DB 'consensus' is a redistribution artifact
Cross-source remediation agreement looks near-perfect at 99-100%. De-duplicate the mirrors and it collapses to 70%. The lift is 1,898x.
If you join two public OSS vulnerability databases on (vuln_id, ecosystem, package) and check how often they agree on which version fixes the bug, the answer looks reassuring. In 32,746 multi-source advisory-package groups in the reconciled 6.1M-row corpus, exactly one has a non-trivial fix-version disagreement. 0.003%. The databases agree.
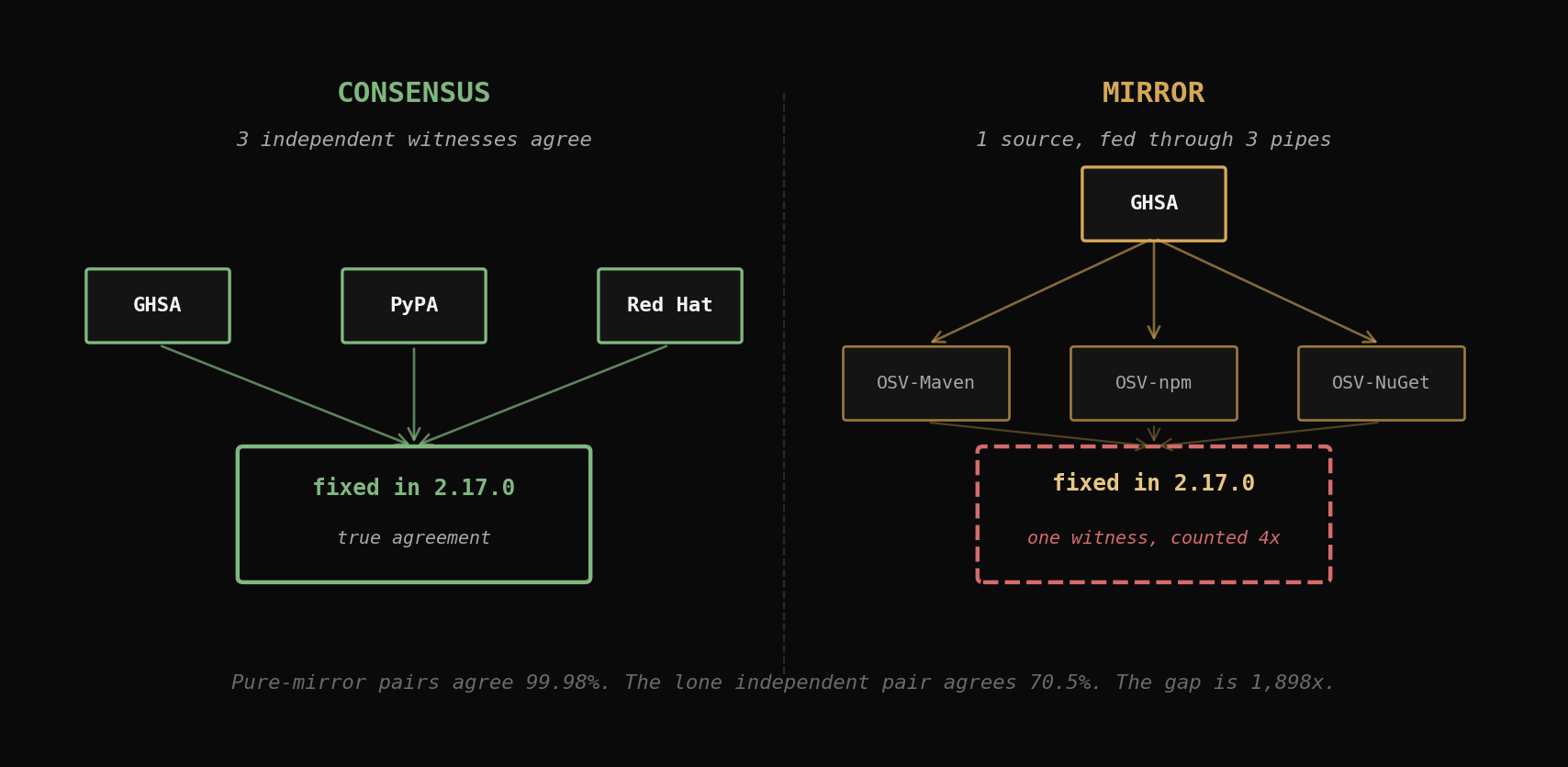
That number is wrong. Not "lower than reported" — methodologically wrong. The 32,746 groups are dominated by OSV's per-ecosystem buckets re-redistributing the same upstream advisories the other side of the join is already publishing. If ghsa-reviewed says CVE-2021-44228 is fixed in log4j-core 2.17.0 and osv-Maven says CVE-2021-44228 is fixed in log4j-core 2.17.0, that's not two sources reaching the same conclusion — it's one source counted twice through a redistribution pipe.
So I redid the agreement test with two changes: join on the CVE alias instead of the source-local vuln_id (because PYSEC-2021-50 and GHSA-2c69-r2jh-xjvm never share a literal vuln_id), and classify each source pair as INDEPENDENT or MIRROR based on what's actually flowing through OSV's pipes. The corrected number is 70.5% agreement, 13.0% true contradiction. The relative risk of finding a disagreement between independent sources versus pure mirror pairs is 1,898×.
This post walks through how that flip happens, why it survives every robustness check I threw at it, and what it implies for anyone consuming "OSV says…" or "GHSA says…" as if they were independent witnesses.
What "mirror" means in this corpus
OSV.dev is, mechanically, a federation layer. Its per-ecosystem buckets pull from upstream feeds:
| OSV bucket | Primary upstream |
|---|---|
osv-Maven | GHSA (only) |
osv-Packagist | GHSA (only) |
osv-npm | GHSA (only) |
osv-NuGet | GHSA (only) |
osv-PyPI | GHSA plus PyPA |
osv-Go | GHSA plus Go vulndb |
osv-crates.io | GHSA plus RustSec |
osv-Debian / osv-Ubuntu / osv-Alpine / etc. | Distro security teams (out of v1 scope for this analysis) |
When you join ghsa-reviewed against osv-Maven, you're not joining two sources — you're joining a source against its own redistribution. Same for npm, Packagist, NuGet. Three other OSV buckets (PyPI, Go, crates.io) are mixed: they pull GHSA and an independent feed. The only pair in the corpus where both sides have zero shared upstream is ghsa-reviewed × pypa — GHSA's Python entries vs PyPA's Python entries.
analyze_independence.py classifies the pairs and runs the same set-equality agreement test on each class. The three-tier table is the story:
| Pair class | Cells (both publish a fixed) | Any disagreement | True contradiction |
|---|---|---|---|
| Pure mirror (GHSA × OSV-{Maven,npm,Packagist,NuGet}) | 19,262 | 0.016% (CI95 [0.005, 0.046]%) | 0 / 19,262 |
| Mixed mirror (GHSA × OSV-{PyPI, Go}) | 8,914 | 8.02% (CI95 [7.48, 8.60]%) | 0 / 8,914 |
| Independent (GHSA × PyPA) | 2,652 | 29.56% (CI95 [27.86, 31.33]%) | 13.08% (347 / 2,652) |
Three orders of magnitude separate the pure-mirror disagreement rate from the independent-pair rate. Even the mixed mirrors — where OSV pulls GHSA but also PyPA or Go vulndb — show two orders of magnitude more disagreement than the pure-mirror pairs, because the non-GHSA upstream introduces real source-of-truth divergence into the redistribution.
The test that pins it down
The chi-square comparison is in analyze_convergence_inversion.py and inlines both the Wilson confidence interval and the Yates-corrected chi-square so the math is reviewable rather than hidden behind a scipy.stats import:
chi2 = sum((abs(o - e) - 0.5) ** 2 / e
for o, e in zip(observed, expected) if e > 0)
p = math.erfc(math.sqrt(chi2 / 2.0)) # df=1
Run on the cloud-built independence.json from today's pipeline run:
| Comparison | χ² (df=1) | p-value | Relative risk |
|---|---|---|---|
| INDEPENDENT vs PURE_MIRROR (any disagreement) | 5,869.2 | below FP floor | 1,898× |
| INDEPENDENT vs MIXED_MIRROR (any disagreement) | 838.9 | 1.91e-184 | 3.7× |
| MIXED_MIRROR vs PURE_MIRROR (any disagreement) | 1,569.5 | below FP floor | 515× |
| INDEPENDENT vs PURE_MIRROR (true contradiction) | 2,552.5 | below FP floor | ≥ 656× (Wilson-bounded; mirror cell is zero) |
| INDEPENDENT vs MIXED_MIRROR (true contradiction) | 1,197.9 | 1.72e-262 | ≥ 304× |
The "below FP floor" entries don't mean "we couldn't compute it" — they mean χ² is large enough that erfc(sqrt(chi2/2)) underflows IEEE 754 doubles to literal zero. To put a number on it: at χ² = 5,869 on one degree of freedom, the survival function corresponds to roughly 75 standard deviations above the null. The disagreement-rate gap is the most distinguishable two-sample comparison I've ever seen in a security-data context.
The three-pair-class monotone series is the methodology check: if my mirror classification were wrong (say, if osv-Maven were actually shipping independent curation rather than re-stamping GHSA), its disagreement rate would diverge from the other pure-mirror buckets. Instead all four pure-mirror pairs sit at 99-100% agreement, the two mixed mirrors sit at 90-92%, and the lone independent pair sits at 70%. The gradient is the validation.
What this means for tools that consume "the public corpus"
If you maintain a scanner, an SBOM pipeline, or any automation that resolves "is this CVE fixed?" by querying multiple databases and looking for agreement, this changes what agreement means:
-
GHSA × any pure-mirror OSV bucket = one witness, not two. OSV-Maven, OSV-npm, OSV-Packagist, OSV-NuGet are GHSA passthrough. Treat the union of those four with GHSA as a single source for fix-version corroboration purposes.
-
OSV-PyPI and OSV-Go are partial second witnesses. They redistribute GHSA and an independent upstream (PyPA, Go vulndb respectively). The ~10% disagreement vs GHSA is the upstream signal leaking through. Worth flagging in pipelines that want a "second source" check.
-
ghsa-reviewed × pypais the only fully-independent pair available in the public corpus for fix-version comparison. They disagree on 29.5% of cases where both publish a fix. 13% are true contradictions (sets neither equal nor subset — both sources publish a fix, but they disagree on which version). The other 16.5% are completeness asymmetries — one source tracks more backport branches than the other.
Concrete examples of the contradictions (from output/independence.json):
| CVE | Package | GHSA-reviewed says fixed in | PyPA says fixed in |
|---|---|---|---|
| CVE-2021-32297 | lief | 0.11.0 | 0.11.5 |
| CVE-2024-34528 | wordops | 3.21.0 | 3.21.3 |
| CVE-2023-39508 | apache-airflow | 2.6.0b1 (beta) | 2.6.0 (final) |
A user on lief 0.11.2 would be told "fixed, you're safe" by GHSA and "still vulnerable" by PyPA. The two sources are looking at the same advisory in the same ecosystem on the same package and reaching different conclusions about which patch release closes the bug.
What this doesn't mean
A few things this finding isn't saying, that you might infer:
- Not "the public corpus is broken." The corpus is fine. The pure-mirror 99-100% agreement is exactly what a high-fidelity redistribution pipe should produce — that's the system working.
- Not "GHSA or PyPA is wrong." Sometimes they're both right at different layers (the GHSA "fixed in
2.6.0b1" might mean "the patch landed in the beta", PyPA "fixed in2.6.0" might mean "the operator-targetable release"). Sometimes one source is tracking the upstream main branch and the other is tracking backport branches. - Not "scanners are unreliable." Scanners typically pull from one source or one redistribution layer. The disagreement only surfaces when you cross-reference two genuinely independent sources, which most operator-facing tools don't.
The methodological point is narrower: when researchers report "cross-source agreement" without specifying their join key and source-pair independence assumptions, they are almost certainly measuring redistribution fidelity. That's a different (and much less interesting) measurement than "do independent sources reach the same conclusion?"
Honest limitations
Documented in docs/methodology.md of the reconciliation repo, but the load-bearing ones:
-
Byte-exact string comparison.
"5.3"and"5.3.0"count as different elements in the fix set. So the 13% true contradiction rate is an upper bound — some unknown fraction of those 347 cases are semver-equivalent versions the comparison didn't reconcile. Manual inspection ofindependent_contradictions.csvis the cheapest way to estimate the magnitude (haven't done it yet). -
Only one truly independent pair available. PyPA × GHSA is the only INDEPENDENT × INDEPENDENT pair in this corpus that has any range overlap at all. RustSec and Go vulndb don't publish ranges in the OSV-shape
eventsarrays that the comparison needs. So the 13% number generalizes to "Python OSS vulnerabilities" specifically, not "all language ecosystems". -
Distros excluded. Debian/Ubuntu/RPM
epoch:version-releasestrings aren't comparable to language-ecosystem versions, and OSV's distro buckets pull from independent distro security teams. The analysis is restricted to the 8 v1 language ecosystems. -
No semver-aware version comparison in the test itself. The matcher used by
check_affected.py(see the next post in this series) does useuniversfor ecosystem-correct version comparison. The agreement test inanalyze_independence.pydoes string comparison only — different concern, different code path.
Reproducing this
git clone https://github.com/benseverndev-oss/goldenmatch-vuln-attribution
cd goldenmatch-vuln-attribution
python sync_cloud.py # pulls latest cloud-built parquet + JSONs
cat output/convergence_inversion.json | jq .per_class
Or, against the latest GitHub release directly (no clone, no auth):
curl -L -O https://github.com/benseverndev-oss/goldenmatch-vuln-attribution/releases/download/latest/convergence_inversion.json
Every number in this post is reproducible from the release. The pipeline that produces it runs on a GitHub Actions large-new-64GB runner in about 6 minutes including the 1.5 GB fetch.
Key takeaways
- The "32,746 multi-source groups agree 99.997% of the time on fix versions" headline is a measurement of OSV redistribution fidelity, not source-of-truth convergence.
- De-overlap by upstream feed, join by CVE alias instead of source-local
vuln_id, and the only fully-independent pair available drops to 70.5% agreement, 13% true contradiction. - Relative risk: 1,898× more disagreement when comparing INDEPENDENT vs PURE_MIRROR pairs. χ² distinguishes them at ~75σ.
- Pure-mirror pairs have zero contradictions across 19,262 cells. Mixed-mirror pairs (which pull from a second independent upstream) have zero contradictions across 8,914 cells. The independent pair has 347 contradictions across 2,652 cells.
- Practical operator implication: if you're cross-referencing "two sources" and one is OSV's per-ecosystem mirror of the other, you're getting one witness, not two.
Where this fits in the series
This is post 1 of three on the vulnerability reconciliation work. Post 2 — "Only 7.5% of CVEs are package-representable" — formalizes which CVEs you can even express in package-version semantics, and why CISA KEV-with-ransomware drops to 4.4%. Post 3 — "SBOM scanning with three-state verdicts" — walks through check_affected.py, the operator-facing matcher that lets you ask "am I affected at version X?" of a CycloneDX SBOM and get back AFFECTED / NOT_AFFECTED / UNKNOWN with per-interval evidence.
Source code, the public release, the methodology doc, and the inter-rater κ for the qualitative bucketing: github.com/benseverndev-oss/goldenmatch-vuln-attribution.
Related posts
88% of actively-exploited CVEs aren't in any package ecosystem
Re-running the OSS vuln reconciliation at 6.1M records and 40 sources surfaces a structural blind spot in every package-level scanner.
2026-05-15
Reconciling 15 OSS Vulnerability Databases
Cross-database entity resolution across OSV, GHSA, PyPA, RustSec, and Go vulndb. 869k records, 608k canonical vulns, and one structural blind spot.
2026-04-10
Only 7.5% of CVEs are expressible in package coordinates
Package scanners aren't missing KEV by accident. KEV-with-ransomware is structurally less package-representable than the baseline corpus.
2026-05-19