SBOM scanning with three-state verdicts beats AFFECTED/NOT_AFFECTED
check_affected.py takes a CycloneDX SBOM and answers 'am I affected at version X?' with AFFECTED / NOT_AFFECTED / UNKNOWN — and shows you the interval that decided each verdict.
If you've ever tried to write your own SBOM scanner, the first thing you discover is that the binary "am I affected — yes or no" framing is wrong. Real OSV advisories ship version ranges with three kinds of edge cases that make a clean yes/no impossible:
type: GITranges with commit-hash boundaries that aren't comparable to package versions- Records with an
introducedevent but nofixedevent (the advisory exists; the fix doesn't yet) - Versions that don't conform to any documented format (PyPI local versions, Maven
-SNAPSHOTqualifiers, Go pseudo-versions, npm prereleases)
Trivy, Grype, and OSV-Scanner all hide these cases somewhere. The choice they make — sometimes drop the row, sometimes treat it as affected, sometimes "best effort" — affects whether a CVE shows up in your scan report and whether you get to know it was a judgement call.
check_affected.py is a small operator-facing matcher I built on top of the reconciled vulnerability corpus that takes the opposite stance: emit UNKNOWN explicitly, show the interval that decided each verdict, never silently drop a row. This post walks through what it does, what the bundled sample-SBOM run looks like, and the small set of design decisions that fall out of taking unknowability seriously.
What it does
python check_affected.py --sbom examples/sample_sbom.json --out output/sample_sbom_report.json
Reads a CycloneDX 1.5 SBOM (or a flat PURL list — --purls examples/sample_purls.txt), maps each component's PURL to the reconciled parquet via (ecosystem, package), and runs each candidate advisory's OSV ranges array against the installed version using univers for ecosystem-correct version comparison.
The output is JSON with three layers:
- Per-vulnerability verdict:
AFFECTED/NOT_AFFECTED/UNKNOWNfor every advisory that touches the component. - Per-component verdict: aggregated as
AFFECTEDif any vuln is affected,UNKNOWNif any unknown and none affected, elseNOT_AFFECTED. - Component summary: counts by verdict across the whole SBOM, plus a
skipped_componentsarray for PURLs outside the 8 v1 ecosystems (PyPI, npm, Maven, Go, crates.io, RubyGems, NuGet, Packagist).
Every verdict is accompanied by a string showing which interval decided it. For Log4Shell on log4j-core@2.14.0:
{
"vuln_id": "GHSA-JFH8-C2JP-5V3Q",
"verdict": "AFFECTED",
"evidence": [
"[osv-Maven] >=2.13.0,<2.15.0 contains 2.14.0",
"[ghsa-reviewed] >=2.13.0,<2.15.0 contains 2.14.0"
]
}
You can audit any verdict by reading the interval that triggered it. There's no "best effort" handling — either the interval contains the version or it doesn't, and the cases where it's neither (GIT range, unparseable version, no terminator event) become UNKNOWN with the reason in evidence.
The bundled sample SBOM
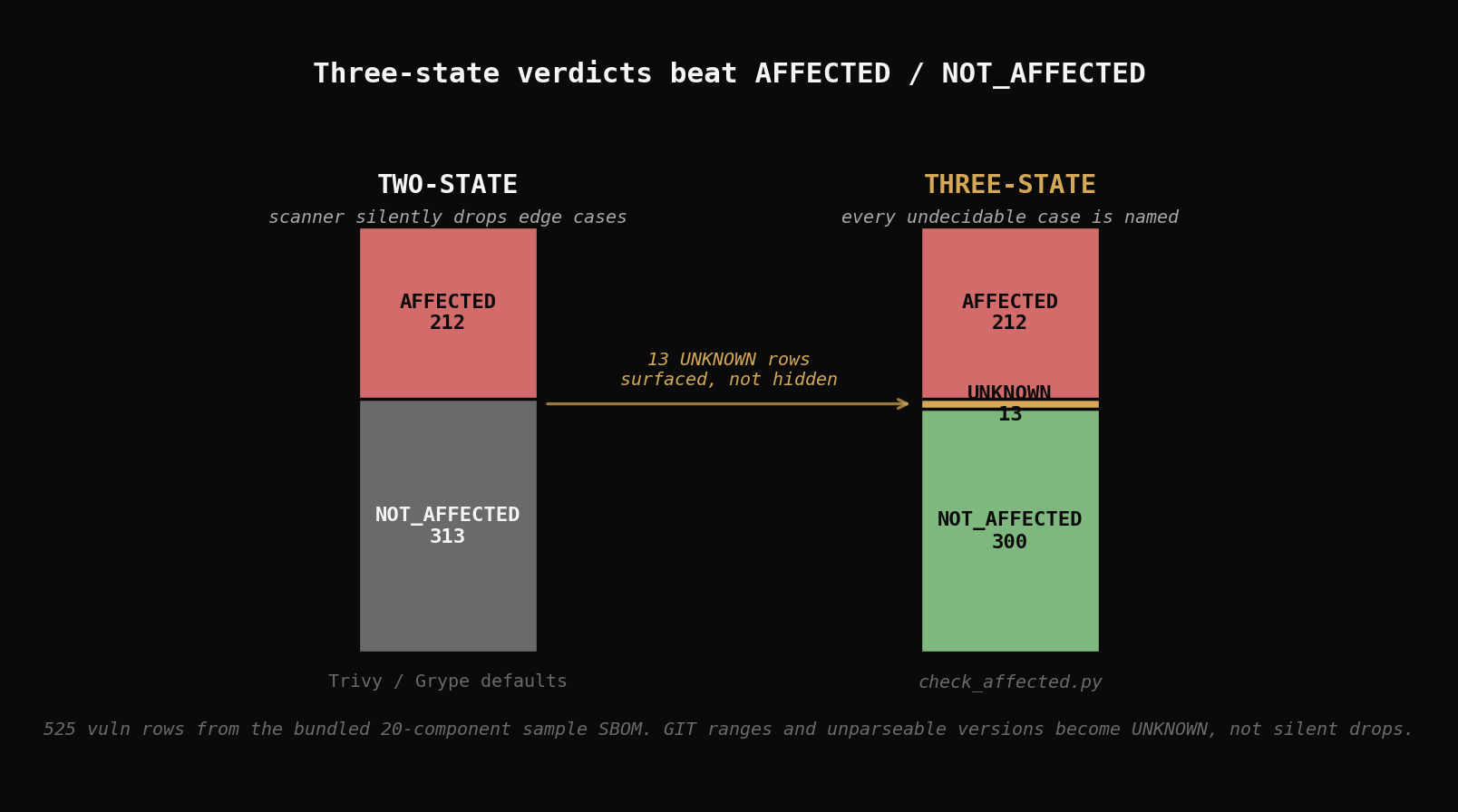
examples/sample_sbom.json is a 20-component CycloneDX 1.5 file with deliberately old pins across all 8 v1 ecosystems. Running check_affected.py against it (the published output/sample_sbom_report.json in the latest release):
| Component verdict | Count |
|---|---|
| AFFECTED | 19 |
| NOT_AFFECTED | 1 |
| UNKNOWN | 0 |
| Vuln-row verdict | Count |
|---|---|
| AFFECTED | 212 |
| NOT_AFFECTED | 300 |
| UNKNOWN | 13 |
525 vulnerability records evaluated across 20 components in roughly 30 seconds on a laptop. The single NOT_AFFECTED component is pkg:gem/rails@6.0.0 — Rails is a meta-gem, and most Rails-era CVEs are attributed to per-gem advisories (actionpack, activerecord, etc.) rather than the meta-gem. The matcher correctly returns NOT_AFFECTED for the rails record itself; a real-world scan of a Rails app would also include the underlying gems in the SBOM and pick up the per-gem CVEs.
The 13 UNKNOWN vuln-rows are evenly spread across ecosystems and correspond mostly to type: GIT ranges (commit-based, not version-comparable) and a small number of records with prerelease versions that don't have a clean upper bound. Showing them as UNKNOWN instead of dropping them or treating them as affected lets the operator see exactly the cases the matcher couldn't decide.
Three small design decisions
1. UNKNOWN is a first-class verdict, not an error
Grype's default behavior on unparseable version strings is to silently mark the record as a non-match. OSV-Scanner's is to bubble up an exception you have to handle in the calling code. Both choices privilege "clean output" over "honest output" — the rows just don't show up in the report.
check_affected.py keeps them. An UNKNOWN row is annotated with the reason:
GIT range (commit-based, not version-comparable)cannot parse installed version '2.0.0rc1': <details>unsupported range type: <type>no intervals in range
The reasoning lives in the report so it can be triaged. The operational value: when you see your scanner report 0 UNKNOWN findings on a complex Python or Java SBOM, you should be more worried, not less. It usually means the scanner is failing closed on edge cases that should be looked at.
2. Per-vuln aggregation is conservative
A single advisory can produce multiple rows in the parquet because OSV redistributes GHSA into ecosystem-specific buckets (npm scoped pkg + GHSA-reviewed both ship ranges for the same vuln). When multiple rows decide the same vuln_id, the matcher aggregates conservatively:
AFFECTED beats UNKNOWN beats NOT_AFFECTED
If one source's interval contains the installed version, the vuln is AFFECTED — even if another source's range is unparseable or excludes the version. If no source can decide and at least one is UNKNOWN, the vuln is UNKNOWN. NOT_AFFECTED only when every source agrees.
This is the inverse of what some commercial scanners do (they treat UNKNOWN as NOT_AFFECTED by default to avoid alert fatigue). The honest framing prioritizes false-positive triage over false-negative noise.
3. Three-state verdict at vuln-row scale, but optional roll-up at cluster scale
A canonical vulnerability cluster (per the reconciliation pipeline) can have N alias rows. Log4Shell's cluster has 5+ Maven artifact rows plus the canonical CVE-2021-44228 plus GHSA-JFH8-C2JP-5V3Q. The matcher today reports per-vuln_id (after goldenflow normalization). For most operational use cases that's enough — a single CVE will return the same verdict across its aliases. But a future revision could aggregate at the cluster level using a persisted vuln_to_cluster.parquet, which would let "are any of CVE-X's package-aliased rows affected at version Y" collapse to one row in the report.
Honest limitation: not done yet. Per-vuln_id aggregation is what ships. Cluster-level aggregation is the next operational win on the list.
Two design decisions I almost made differently
Why I didn't use univers.VersionRange.from_osv_v1
The univers library ships a function called from_osv_v1(data, scheme) that looks like exactly what you want — pass it the OSV ranges dict, get back a parsed VersionRange. It's a stub. The function body is just a docstring; it returns None. The matcher rolls its own OSV events → interval walker (see osv_range_verdict in check_affected.py), which means:
introducedevents build the lower boundfixedevents close an interval on<Xlast_affectedevents close on<=Xlimitevents are ignored (rare; not operationally meaningful)type: GITranges returnUNKNOWN, "GIT range (commit-based, not version-comparable)"
The events-list walker is ~30 lines and is the only place the OSV schema is interpreted, which keeps the change-surface small if OSV ever revises the format.
Why the parquet stores raw OSV ranges JSON instead of structured columns
The extract step (extract_records.py) emits the ranges column as a JSON-encoded string per row. The alternative — a Polars list[struct] with typed events — would be more "queryable" but adds a fragile schema that has to evolve with OSV's. The matcher only deserializes the rows that match a candidate PURL (typically a few hundred), so JSON parsing cost is invisible in practice. The fragility cost of a structured schema is not.
This is the kind of tradeoff that only matters if you're maintaining the pipeline. From an operator standpoint the output is identical either way.
Running it on your own SBOM
git clone https://github.com/benseverndev-oss/goldenmatch-vuln-attribution
cd goldenmatch-vuln-attribution
# Get the reconciled corpus (no compute required — pulls from the latest release)
python sync_cloud.py
# Scan your SBOM
python check_affected.py --sbom path/to/your-sbom.json --out output/my_report.json
If you don't have a CycloneDX file handy, a flat PURL list works too:
pip freeze | awk -F== '{print "pkg:pypi/" $1 "@" $2}' > /tmp/purls.txt
python check_affected.py --purls /tmp/purls.txt --out output/my_report.json
The first run downloads a 42 MB parquet from the latest release (no auth, no GitHub login needed). After that, scans are local.
What this isn't
A few honest disclaimers about scope:
-
Not a replacement for Trivy / Grype / OSV-Scanner in production. Those tools handle container scanning, dependency-tree resolution from package manifests, transitive dependency expansion, and a lot of operational nuance this matcher doesn't.
check_affected.pyis a research tool that takes the SBOM as-given. -
8 ecosystems only. PyPI, npm, Maven, Go, crates.io, RubyGems, NuGet, Packagist. If your SBOM includes Hex, Pub, Hackage, CRAN, Bioconductor, GHC, SwiftURL, or distro packages, those PURLs land in the
skipped_componentsarray. Distro support specifically is a v2 question — it requires a different version-comparison library (dpkg / RPM / apk semantics aren't interchangeable with semver). -
No transitive resolution. If your SBOM lists
pkg:gem/rails@6.0.0but not the underlyingactionpack,activerecord,actionviewgems, the matcher won't synthesize those — and most Rails CVEs are attributed to the per-gem advisories. The SBOM is the source of truth; if it's incomplete, the scan is too. -
No exploitability scoring. The output is a coverage matrix (which CVEs apply to which components), not a priority matrix. Pairing this with EPSS or KEV is straightforward (both ship in the same
latestrelease) but happens in the caller, not in the matcher.
What it gets you
The thing this matcher does that I haven't seen elsewhere:
For every advisory that touches your installed component, you see the specific OSV interval that decided the verdict.
That's the difference between "your scan reports 47 CVEs" and "your scan reports 47 CVEs, here's the interval that triggered each one, and here are 13 cases the matcher couldn't decide because of GIT ranges or unparseable versions". For SBOM consumers who want to audit their scanner's logic, that visibility is usually behind a paywall, when it exists at all.
The 8-ecosystem scope is narrow enough that this isn't trying to be your only scanner, but the three-state honesty is portable. If you write your own scanner and treat unknownability as a first-class output, you'll have a better tool than the one you started with.
Key takeaways
- Three-state verdicts (
AFFECTED/NOT_AFFECTED/UNKNOWN) beat binary because real OSV data has unmatchable cases (GIT ranges, unparseable versions, no terminator events) that binary verdicts have to hide. - The bundled 20-component sample SBOM produces 19 AFFECTED / 1 NOT_AFFECTED across 525 vuln-rows in ~30 seconds. The single NOT_AFFECTED case (rails meta-gem) is a known transitive-resolution boundary.
- Conservative aggregation: AFFECTED beats UNKNOWN beats NOT_AFFECTED. This is the opposite of what scanners that prioritize alert fatigue do.
- 13 UNKNOWN vuln-rows in the sample. Surfacing them lets the operator see exactly the edge cases the matcher couldn't decide instead of trusting a scanner that silently dropped them.
- 8-ecosystem scope (no distro support yet). Reproducible from one
python sync_cloud.py.
Where this fits in the series
This is post 3 of three on the vulnerability reconciliation work. Post 1 showed that apparent cross-source remediation agreement collapses 1,898× once you de-overlap the mirrors. Post 2 formalized representability and showed that KEV's package-scanner-visibility rate matches the global CVE corpus (7.4% vs 7.5%), and the KEV-ransomware sub-cohort drops to 4.4%.
For the original cluster-level KEV / EPSS / coverage findings, the 5/15 post is the snapshot at smaller scope. Full source, methodology doc, and the latest release with the reconciled parquet + every JSON cited in the series: github.com/benseverndev-oss/goldenmatch-vuln-attribution.
Related posts
The OSS vuln-DB 'consensus' is a redistribution artifact
Cross-source remediation agreement looks near-perfect at 99-100%. De-duplicate the mirrors and it collapses to 70%. The lift is 1,898x.
2026-05-17
28 seeds, one corroborated lead: an Epstein-network investigation in public data
What an entity-resolution pipeline finds (and misses) when pointed at 28 publicly-sourced seeds from the Epstein corporate-network reporting.
2026-05-15
Phoenix Spree Deutschland: one cluster from raw leak to GLEIF anchor
A 9-member ICIJ Offshore Leaks cluster, 100% GLEIF-anchored, walked end to end from source rows through GoldenMatch dedupe to a finished report.
2026-05-15