The honest math on building your own MDM
A realistic person-month estimate for building an MDM platform in-house: engine, pipeline, workbench, audit, survivorship, connectors. Plus the year-2 maintenance cost nobody plans for.
Every six months or so, somebody asks me whether they should just build their own MDM platform.
The conversation usually starts something like this: "We got a quote from Reltio for $80k a year. That's two engineers for six months. We have two engineers. Why don't we just build it?"
The math is tempting. The math is also wrong, and it's wrong in ways that are systematically underestimated. This post is the honest version, drawn from having actually built the thing twice (once as a contractor, once as the founder of an MDM SaaS) and watched maybe a dozen other teams try it.
I'll walk through the actual components, give realistic person-month estimates, and then talk about the year-2 cost that nobody plans for. By the end you should be able to do the build-vs-buy math for your own situation without flattering yourself in either direction.
The components you don't think about
If you've never built an MDM platform, you probably think of it as "the matching algorithm." That's the most visible piece, so it's the piece you imagine when you imagine the build.
The matching algorithm is roughly 15% of the work.
Here's what's actually in an MDM platform:
- The matching engine. Blocking, scoring, clustering. The visible part.
- The data pipeline. Ingestion from N source systems, scheduling, retries, partial loads.
- The workbench / UI. Where stewards review ambiguous matches, approve/split/merge, configure rules.
- Survivorship. Field-by-field rules for which value wins when records merge.
- The audit trail. Tamper-evident logs of every match, merge, correction, override.
- Lineage. Tracing a golden record back to the source rows that contributed.
- Connector library. Salesforce, HubSpot, Stripe, Postgres, Snowflake, BigQuery, S3, the dozen-plus systems your customer data lives in.
- Multi-tenancy / scoping. Permissions, org structure, environments.
- Quality monitoring. Drift detection, F1 tracking over time, alerting when match quality regresses.
- Deployment + ops. Containers, IaC, secrets, monitoring, on-call.
Each of those is a system. Some are bigger than others. None are free.
Realistic person-month estimates
I'll give ranges. The low end assumes a senior engineer with prior experience in the relevant domain. The high end assumes a competent generalist who has to learn as they go. Most teams land in the middle.
| Component | Person-months (range) |
|---|---|
| Matching engine | 3-6 |
| Data pipeline | 2-4 |
| Workbench UI | 4-8 |
| Survivorship | 1-2 |
| Audit trail | 2-3 |
| Lineage | 1-2 |
| Connector library (per source × 8 sources) | 8-16 |
| Multi-tenancy / scoping | 1-2 |
| Quality monitoring | 1-2 |
| Deployment + ops | 1-2 |
| Total (v1, minimum viable) | 24-47 person-months |
Let me defend each number briefly, because these always provoke pushback from teams who've never tried.
Matching engine, 3-6 months. The naive version of blocking + scoring + Union-Find is a one-week exercise. The version that actually performs well on real data — with adaptive blocking, scorer ensembles, threshold tuning, postflight reporting on ambiguous merges — is months. The matching engine is where I see the most "I'll just build the algorithm in an afternoon" optimism. The afternoon-version produces an F1 around 0.5. The version that lands at 0.8+ on a real benchmark takes months.
Pipeline, 2-4 months. Source-by-source ingestion is fine for week 1. Then someone asks "can we incrementally load instead of full-refresh?" and you spend a month on watermark logic. Then someone asks "what happens when an upstream API rate-limits us?" and you spend three weeks on retry and backoff. Then someone asks "can we replay yesterday's pipeline?" and you spend a month on event-sourcing your pipeline state.
Workbench UI, 4-8 months. This is the biggest single under-estimate. A "good enough" workbench has: a review queue, a cluster-detail view with side-by-side field comparison, a survivorship-rule editor that non-engineers can use, an audit-log viewer with filtering, a connector-management UI, a permissions/scoping UI. Each of those is a 2-4 week piece on its own. Six months is the low end if you have a competent front-end engineer.
Connector library, 8-16 months total. I keep meeting teams who say "we'll just write one connector at a time as we need them." That's true. They take 1-2 weeks each, and you'll write 8 of them in year 1 because every new department wants their source ingested. Two months × 8 sources = 16 person-months. The hosted MDM vendors all ship with 30-100 connectors out of the box because they've been writing them for a decade.
Audit + lineage, 3-5 months combined. If you're in any regulated environment, "an audit chain" doesn't mean "a log table." It means tamper-evident logs with cryptographic hashing, per-row provenance walkable from golden record back to source, immutable storage, compliance-ready export. Your auditors will ask. You will spend 3-5 months getting this right.
Total at the low end: 24 person-months. At the high end: 47. With two engineers, that's a 12-24 month project to ship v1.
The year-2 cost nobody plans for
The build estimate is honest. The year-2 estimate is where the wheels actually come off.
In year 2 you have:
- Dependency upgrades. Polars major-version bump every quarter. Pandas API changes. Snowflake connector deprecations. Your dependencies churn whether you like it or not, and "upgrade and re-test the matching engine" is a real week of engineering time per quarter.
- Edge cases. Your engine handles 99% of records cleanly in year 1. The 1% trickle in over year 2 — Unicode normalization issues, timezone-aware dates that aren't, source systems that change their schema without telling you. Each edge case is a half-day of debugging.
- On-call. The pipeline runs every day. Sometimes it breaks. When it breaks at 3am, someone has to get paged. If your team is 2 engineers, you've just signed up both of them for permanent on-call rotation on a system that isn't your product.
- New connector requests. Marketing wants Iterable ingested. Sales wants Outreach ingested. Each request is 1-2 weeks. Each request comes from someone who thinks it'll be quick.
- Quality regression. Six months in, someone notices a match-quality issue on a specific source. Was it always like this? Did a Polars upgrade change scorer behavior? Did someone bump a threshold? You need the benchmark + drift monitoring you didn't build in year 1, and now you have to retrofit it.
- Knowledge concentration. Your original engineer — the one who built half the engine — gets a job offer at Stripe. The institutional knowledge of "why is the cluster_id reset every other Tuesday" leaves with them.
Year-2 cost: 0.5-1 full-time engineer dedicated to maintenance. That's $150k-$300k/year in loaded cost. Forever.
The true cost over 3 years
Conservative version, two-engineer team, 24-month build, 0.75 FTE maintenance ongoing:
- Year 1 build: 2 engineers × 12 months × $200k loaded = $400k
- Year 2 maintenance + scope creep: 0.75 FTE × $200k = $150k
- Year 3 maintenance: 0.75 FTE × $200k = $150k
- 3-year TCO of building: $700k
For comparison:
- Reltio at $80k/year × 3 years = $240k
- Mid-tier MDM SaaS (e.g., Golden Suite Pro) at $1.2k/year × 3 years = $3.6k
- Mid-tier MDM SaaS at scale (e.g., Golden Suite Enterprise, $30k/year) × 3 years = $90k
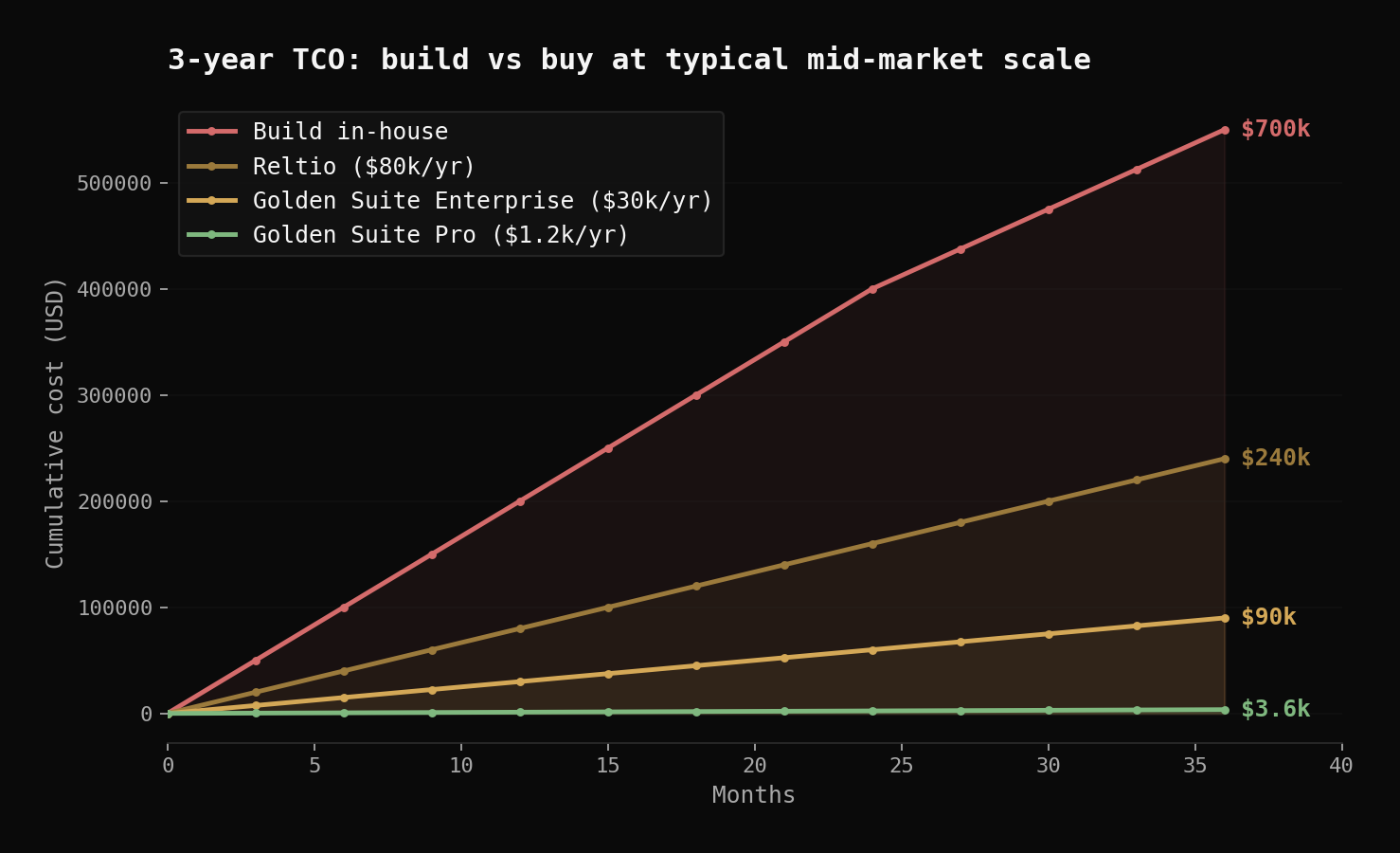
The math isn't even close. Building MDM in-house is one of the worst ROI engineering decisions a mid-market company can make, and it's also one of the most common.
When building actually wins
I want to be fair about this because the post that pretends building is never right is a sales pitch. Building is genuinely the right call when:
- You have unusual matching requirements that no vendor handles. Healthcare patient matching with PHI constraints, geospatial entity resolution, government-specific record-linkage where the rules are statutorily defined.
- You're at a scale where vendor pricing breaks. If you have 500M+ customer records and the vendor's per-record pricing makes the deal $2M/year, you can build cheaper.
- MDM IS your product. If you're selling MDM-as-a-feature inside a larger platform, building the engine is part of your moat.
- Your existing data engineering team has bandwidth and wants the project. Sometimes the build is the right call because the team genuinely wants to build it and the institutional skill compounds. This is rarer than people think but it's real.
Even when building wins, the right shape is usually "build on top of an open-source engine, don't build the engine." goldenmatch, dedupe, splink — these are all MIT-licensed engines you can drop in. Build the operating surface around them; don't rebuild the matching algorithm.
When buying actually wins
Buying wins for the boring middle case. You have 50k-2M customer records. You have 3-6 source systems. You have one data engineer and an analytics person. You have a real business problem (attribution / pipeline reporting / billing reconciliation) that the duplicates are blocking. You don't have 24 months to wait for a custom build.
For this case, the buy-vs-build math is basically settled: buy. The only question is which tier (see the Reltio alternatives post for the tier breakdown).
The argument the "build" side usually makes against this is "but vendors will lock us in." That's true, and it's also true of any database, ORM, cloud provider, CI system, or analytics tool you currently use. Vendor lock-in is a cost, not a disqualifier. The way to mitigate it is to pick a vendor whose data model is exportable and whose pricing is predictable — not to refuse to use any vendor at all.
What to do this week
If you're currently in a build-vs-buy debate:
- Do the honest math. Use the table above. Multiply by your actual loaded cost per engineer, not the discounted number. Don't subtract "but they're already employed" — opportunity cost is a real cost.
- Pilot the buy side. Pick one or two vendors at the tier that fits your size. Most have free trials or free tiers. Run a one-week PoC on your actual data. See if the match quality is good enough.
- Only build if the pilot visibly fails. "Fails" means the vendor can't handle your specific edge cases, not that the UI isn't perfect. Mid-tier MDM tools have the same match quality as enterprise tools at this point — the gap is operating surface, not engine.
- If you build, build on top of an OSS engine.
goldenmatch,dedupe,splink. Whichever you pick, you save 3-6 months on the engine itself and you stay close to a community that's solving the same problems.
The honest answer to "should we build our own MDM" is almost always no. The honest answer to "should we build all of our own MDM" is almost always no even when "build" wins — the engine is open source already, and building it again is the wrong place to spend the bandwidth.
Golden Suite is the open-source MDM workbench I build, exactly because I think the boring middle case (50k-2M records, 3-6 sources, one data engineer) is the worst-served buyer in the MDM market. Try it on your own data or read the build-vs-buy comparison.
Related posts
Reltio alternatives that don't cost $5,000 a month
An honest field guide to MDM tools when your company can't justify a Reltio license. Covers DIY, the open-source middle, and the SaaS landscape — with realistic price ranges.
2026-05-13
Pipe Your SaaS Data to Your Warehouse: A Funnel That Doesn't Own It
Most MDM tools want to be your source of truth — you query their store. bensevern.dev inverts that: it's a matching funnel between your SaaS sources and your warehouse, then hands the data back. Here's what that looks like end-to-end.
2026-05-23
10 Data Problems Every Pipeline Hits and Their Fixes
The same 10 data quality issues show up in every dataset: phone formats, broken dates, null variants. Here's what each looks like and how to fix it.
2026-04-04