Deduplicating 401K Equipment Records with LLM Calibration
We ran GoldenMatch on 401,125 bulldozer auction records from Kaggle. Iterative LLM calibration learned the optimal match threshold from just 200 pairs (~$0.01). ANN hybrid blocking recovered 949 records that string blocking missed.
Equipment auction data is messy. The same Caterpillar D6 bulldozer sells three times across different states, and each auction house records the model slightly differently. "580 Super L" in one record becomes "580SL" in another. "D6H LGP" appears alongside "D6H" — same machine, different level of detail.
We took the Kaggle Bulldozer Blue Book dataset — 401,125 auction records across 53 columns — and threw it at GoldenMatch to see what happens.
The result: 27,937 duplicate clusters, 384,650 records matched, and the LLM learned the perfect threshold from just 200 pairs. Total LLM cost: $0.01.
The Dataset
The Bulldozer dataset comes from a Kaggle competition on predicting auction sale prices. Each row is a single auction transaction:
- 401,125 rows, 53 columns
- Key fields:
fiModelDesc(model description),fiBaseModel(base model code),YearMade,state,SalePrice,ProductGroup,fiProductClassDesc - The same machine appears multiple times across different auctions, states, and years
- Model descriptions vary: "580 Super L", "580SL", "580super l" are the same machine
- 90+ oversized blocking groups (e.g., "D000" with 61,861 records sharing the same soundex code)
The Challenge: Auto-Config Gets It Wrong
Our first attempt used GoldenMatch's zero-config mode:
result = goldenmatch.dedupe_df(df, llm_scorer=True)
Zero matches. The auto-config misclassified the columns:
| Column | Expected Type | Auto-Config Said |
|---|---|---|
SalesID | Identifier | "phone" (7-digit integers look like phone numbers) |
SalePrice | Numeric/Price | "zip" (5-digit round numbers look like zip codes) |
fiModelDesc | Text (most important!) | Dropped (fuzzy field limit of 5, picked by column order) |
The ID pattern was checked last in the classification chain, so data profiling overrode the name heuristic. And fiModelDesc — the single most discriminating field — was arbitrarily dropped because it appeared after five other columns.
We fixed all three issues in v1.2.6:
- ID patterns checked first —
SalesIDnow correctly classified as "identifier" - Price/cost/amount patterns added —
SalePricestays "numeric" instead of becoming "zip" - Utility-based field ranking — fields ranked by
cardinality x completeness x string_lengthinstead of column order.fiModelDesc(high cardinality, long strings) naturally ranks aboveUsageBand(3 values, 4 chars)
The Configuration
Here's the optimal config we landed on:
import goldenmatch
from goldenmatch.config.schemas import (
GoldenMatchConfig, MatchkeyConfig, MatchkeyField,
BlockingConfig, BlockingKeyConfig, LLMScorerConfig, BudgetConfig,
)
config = GoldenMatchConfig(
# Multi-pass blocking with ANN fallback
blocking=BlockingConfig(
strategy="multi_pass",
passes=[
BlockingKeyConfig(
fields=["fiModelDesc", "state"],
transforms=["lowercase", "strip"],
),
BlockingKeyConfig(
fields=["fiModelDesc", "ProductGroup"],
transforms=["lowercase", "strip"],
),
BlockingKeyConfig(
fields=["fiBaseModel"],
transforms=["lowercase", "soundex"],
),
],
max_block_size=1000,
skip_oversized=True,
ann_column="__equipment_text__", # ANN fallback
ann_top_k=20,
),
# Weighted fuzzy scoring
matchkeys=[MatchkeyConfig(
name="equipment_match",
type="weighted",
threshold=0.90,
fields=[
MatchkeyField(field="fiModelDesc", scorer="ensemble",
weight=2.0, transforms=["lowercase", "strip"]),
MatchkeyField(field="fiBaseModel", scorer="jaro_winkler",
weight=1.5, transforms=["lowercase", "strip"]),
MatchkeyField(field="fiProductClassDesc", scorer="token_sort",
weight=1.0, transforms=["lowercase", "strip"]),
MatchkeyField(field="YearMade", scorer="exact", weight=0.8),
MatchkeyField(field="state", scorer="exact", weight=0.3),
MatchkeyField(field="ProductGroup", scorer="exact", weight=0.5),
],
)],
# LLM calibration
llm_scorer=LLMScorerConfig(
enabled=True,
provider="openai",
auto_threshold=0.95,
candidate_lo=0.85,
candidate_hi=0.95,
batch_size=75,
max_workers=3,
budget=BudgetConfig(max_cost_usd=1.00, max_calls=500),
),
)
result = goldenmatch.dedupe_df(df, config=config)
Three blocking passes catch different types of duplicates. The ensemble scorer (max of jaro_winkler, token_sort, and soundex) handles model description variants. Exact scorers on year, state, and product group anchor the match.
ANN Hybrid Blocking: Don't Skip Oversized Blocks
The multi-pass blocking produced 37,492 blocks, but 90+ were oversized (>1,000 records) and would normally be skipped. The soundex pass creates blocks like "D000" with 61,861 records — every Caterpillar D-series machine in the dataset.
Skipping these blocks means missing legitimate duplicates. But processing them is too expensive (61K records = 1.9 billion pair comparisons).
ANN hybrid blocking solves this. When a block is oversized, GoldenMatch:
- Extracts unique text values from the block (61,861 records might have only 187 unique model descriptions)
- Embeds the unique texts via Vertex AI (
text-embedding-004) - Uses FAISS to find nearest neighbors among the unique texts
- Groups neighbors into sub-blocks via Union-Find
The result: 15 oversized blocks were recovered into 363 sub-blocks, matching 949 additional records that string blocking missed entirely. Embedding 187 unique texts took 4 seconds.
Blocks that are truly massive (>10x max_block_size, like "D000" at 61K) are still skipped — the soundex is too coarse to be useful.
Iterative LLM Calibration: 200 Pairs Instead of 37,500
After fuzzy scoring, GoldenMatch found 13.2 million pairs above 0.85. Of these, 13.1 million scored above 0.95 (auto-accepted) and 135,530 fell in the borderline range (0.85-0.95).
The old approach would score all 135,530 borderline pairs via the LLM — that's 1,807 API calls at batch_size=75, roughly $0.50 and 25 minutes. On our first attempt, it actually produced 23.7 million candidates and hit OpenAI's rate limit after 80 batches.
Iterative calibration takes a different approach:
Round 1: Sample 100 pairs spread across the 0.85-0.95 score range. Send to GPT-4o-mini. Result: 2 matches, 98 non-matches. Grid search finds threshold = 0.946.
Round 2: Sample 100 pairs near the threshold (0.916-0.948). Result: 11 matches, 89 non-matches. Updated threshold = 0.947. Delta = 0.001 (below convergence threshold of 0.01).
Converged. Apply threshold 0.947 to all 135,530 candidates: 1,533 promoted to match, 133,810 kept at their fuzzy score.
Total: 200 pairs scored, 2 API calls per round, $0.01, 42 seconds.
The key insight: we don't need to ask the LLM about every borderline pair. We just need to learn where the boundary is. A stratified sample of 100 pairs across the score range is enough to find it, and a focused sample near the boundary confirms it.
Results
| Metric | Value |
|---|---|
| Total time | 323 seconds |
| Records matched | 384,650 (95.9%) |
| Unique (singletons) | 16,475 (4.1%) |
| Duplicate clusters | 27,937 |
| Golden records | 27,426 |
| LLM pairs scored | 200 |
| LLM cost | ~$0.01 |
| ANN sub-blocks | 363 (from 15 oversized blocks) |
| Cluster confidence >= 0.4 | 87.7% |
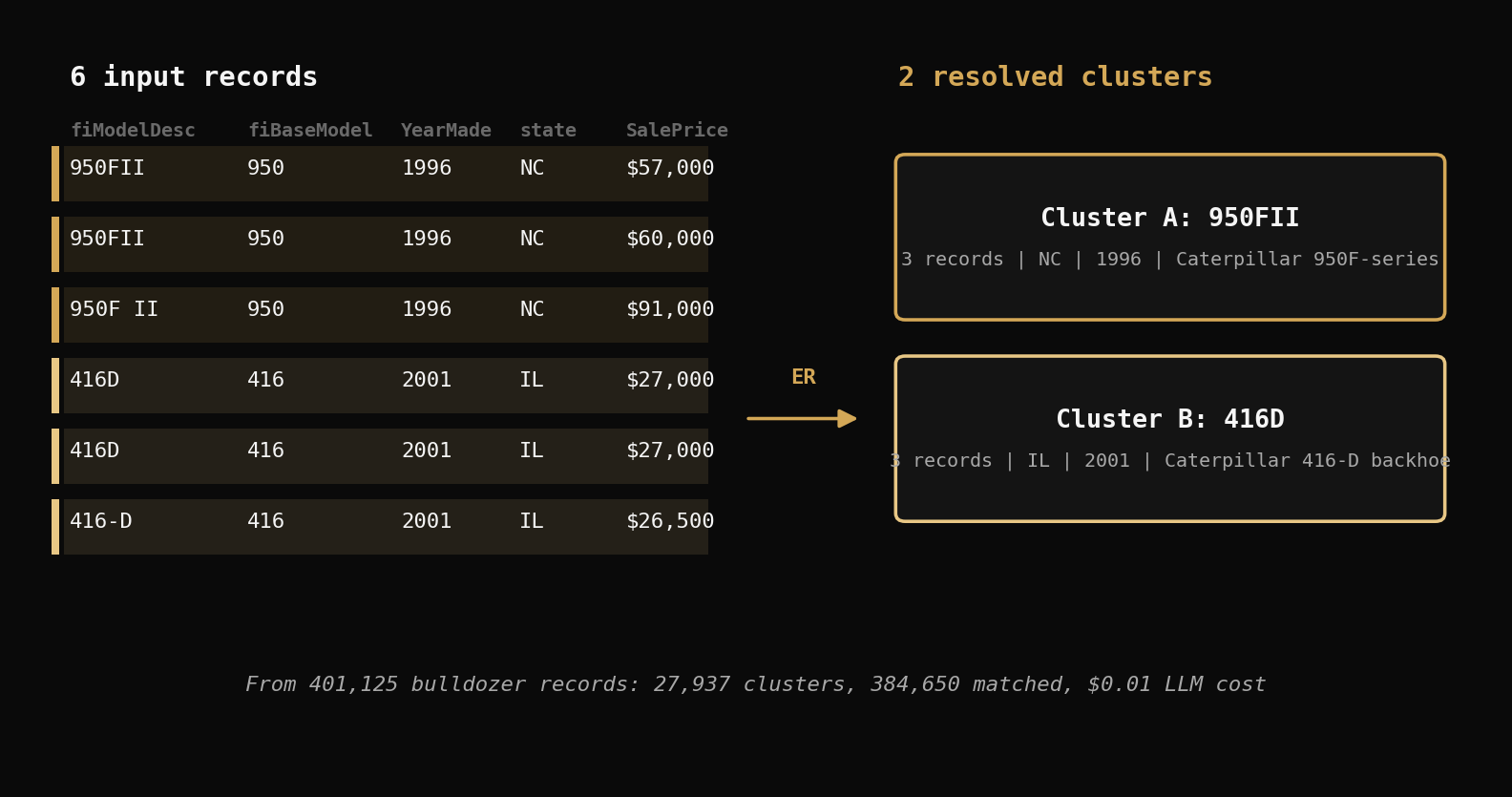
Example Clusters
Cluster 2 (size 3):
950FII | 950 | 1996 | North Carolina | $57,000
950FII | 950 | 1996 | North Carolina | $60,000
950FII | 950 | 1996 | North Carolina | $91,000
Cluster 8 (size 3):
416D | 416 | 2001 | Illinois | $27,000
416D | 416 | 2001 | Illinois | $27,000
416D | 416 | 2001 | Illinois | $26,500
Cluster 33 (size 4):
750BLT | 750 | 1000 | Michigan | $14,000
750BLT | 750 | 1000 | California | $18,000
750BLT | 750 | 1000 | Alabama | $21,500
750BLT | 750 | 1000 | Arkansas | $13,000
Same equipment model, same year, same or different states, different sale prices. These are the same machine being resold at different auctions.
Accuracy: Optimal vs Previous
We compared the v1.2.6 optimal config against a simpler string-only config:
| Metric | String Only | Optimal (ANN + LLM) |
|---|---|---|
| Clusters | 28,703 | 27,937 |
| Records matched | 383,701 | 384,650 (+949) |
| Confidence >= 0.4 | 77.1% | 87.7% |
| LLM threshold | 0.909 (too permissive) | 0.947 (precise) |
| LLM pairs promoted | 8,647,816 | 1,533 |
The string-only run's LLM threshold was too low (0.909), promoting 8.6 million pairs — many of which were different equipment variants sharing a model number (e.g., "550BLT" vs "550JLGP"). The optimal run's tighter threshold (0.947) correctly kept these as separate records.
The 34 records that were "lost" (matched in the string-only run, singletons in optimal) were verified as false positives — different equipment variants with generic model numbers like "530", "550", "325" that have thousands of records across 10+ variants.
Try It Yourself
pip install goldenmatch==1.2.6
The full example is at examples/equipment_dedup.py in the GoldenMatch repo. Download the Bulldozer dataset from Kaggle and run:
export OPENAI_API_KEY=sk-...
export DATA_PATH=Train.csv
python examples/equipment_dedup.py
ANN hybrid blocking is optional — it works without Vertex AI, just skips oversized blocks like before. The LLM calibration alone is the biggest accuracy improvement.
What's Next
The iterative calibration approach opens up a path to persistent learning: save the LLM's threshold decisions across runs, so subsequent deduplications start with a pre-calibrated threshold instead of learning from scratch. We're building this as part of GoldenMatch's Learning Memory system.
For now, v1.2.6 is live on PyPI and the full configuration is documented in the LLM Integration guide and Blocking Strategies guide.
Related posts
GoldenMatch vs. BPID: Testing Against an EMNLP Benchmark
We benchmarked GoldenMatch on Amazon's BPID dataset — 10,000 adversarial PII pairs. With DOB parsing and Vertex AI embeddings, we hit 0.750 F1 — matching Ditto with zero training data.
2026-04-02
Entity Resolution on 208K Real Records with Golden Suite
We ran the full Golden Suite pipeline on 208,505 real NC voter registration records. 61 quality findings, 197K addresses cleaned, 10,718 duplicate clusters found — all in 34 seconds with zero config.
2026-03-30
Wallet Attribution at Scale: ER on 13M Blockchain Records
Running entity resolution across 10 public blockchain attribution datasets surfaces cross-jurisdictional sanctions and universal infrastructure patterns.
2026-04-09