Joining EPA ECHO to HIFLD prison data when the spatial join fails
A fuzzy-join walkthrough for the open issue UCLA's Carceral Ecologies lab is sitting on: matching ~7,000 carceral facilities across federal datasets that share no clean key, no consistent industry code, and a lat/long column full of zipcode centroids.
UCLA's Carceral Ecologies lab has an open GitHub issue (#1) that reads like the canonical entity-resolution problem statement, just dressed in EPA acronyms:
The first step to analyzing the EPA data as they relate to carceral facilities is to filter the immense ECHO data set down to just carceral facilities. We have identified HIFLD as the best data set for carceral facilities as the DOJ data is over a decade old. Performing this join is easier said than done as the ECHO data do not have consistent industry labeling (SIC or NAICS codes) that would make for an easy join.
Executing a spatial join between the lat and long of ECHO data and the shapefiles of HIFLD appears difficult because the vast majority of lat/long data in ECHO are zipcode centroids.
That second paragraph is the punchline. The two obvious joins both break.
The lab's Mississippi pilot found that only ~7% of OPEN MS prisons in HIFLD are registered in ECHO. Either 93% of Mississippi prisons are exempt from environmental regulation (unlikely), or the join is missing rows that should match. Both are problems worth solving, but they're different problems, and you can't tell them apart without a clean match first.
Below is how I would attack this. Same pipeline I've been running on shell-company reconciliation against ICIJ + GLEIF, the OFAC sanctions ledger, and an open-source vulnerability-DB tangle. Different vocabulary, same shape.
Why the obvious joins fail
Four ways this problem refuses to behave:
1. Industry codes are wrong. ECHO's SIC and NAICS fields for carceral facilities are a mess. The legitimate codes (9223 SIC, 922140 NAICS) only get applied when a facility self-identifies as a correctional institution at registration time. A jail run as part of a county utility district lands under 9199 General government. A federal detention center contracted to a private operator might be filed under 5611 Administration of educational programs if the contractor's primary classification leaked in. There's no central authority normalizing this.
2. Lat/long is mostly noise. ECHO's latitude/longitude column is populated by the registering agency. The agency is allowed to use the zipcode centroid when the precise location isn't required for the program. Spot-checking five state prison entries: three are centroids accurate to ~5 km, two are precise. A st_distance join with any tolerance loose enough to capture the centroid cases (~5 km) will produce false positives for any two facilities sharing a zip.
3. Facility names are inconsistent. USP YAZOO CITY vs United States Penitentiary, Yazoo City, MS vs FCI Yazoo City (USP) are the same place. CI ADAMS COUNTY and Adams County Correctional Institution are the same place. Some are clean, some are abbreviated, some carry the operator's name (CoreCivic Yazoo City), some carry the contracting agency (BOP USP Yazoo City).
4. Some facilities exist in HIFLD but not ECHO. This isn't a join failure, it's a registration gap. Issue #2 names it: prisons over 25 residents should be registered under the Safe Drinking Water Act, but many large facilities have no FRS ID. Some are registered at the state level only. Some are unregistered in violation of the rule. You can't solve this with matching alone, but a clean match tells you which facilities have the gap.
The shape of the right solution
The honest framing: this is a multi-attribute fuzzy join across two datasets where no single field is sufficient and every field is noisy. The textbook answer is a composite scorer that weights several weak signals into a single confidence score.
For ECHO↔HIFLD specifically, the working signals are:
| Signal | Strength | Watch for |
|---|---|---|
| Normalized facility name | High when present | Operator/agency prefixes, "FCI" vs "Federal Correctional Institution" |
| State (2-letter) | Hard filter, near-zero false positives | Multi-state contractors |
| City | Strong on state subset | Same city, different facilities (e.g. Yazoo City has 3) |
| Street address (when present) | Strong when available, often missing in HIFLD | USPS-normalize first |
| ZIP code | Weak; many facilities cluster by zip | Use only as a tiebreaker |
| Lat/long | Weak (centroids), but useful at the cluster level | Use a generous tolerance and treat as one signal among many, never as the primary key |
| Operator name | Tiebreaker when both sources have it | CoreCivic vs CoreCivic, Inc. vs CCA (legacy name) |
The right pipeline has three stages: block, score, decide.
Block first
Don't compare every ECHO row against every HIFLD row. With ~1.7M ECHO facilities and ~7K HIFLD carceral facilities, the full cross-product is ~12 billion pairs. Filter aggressively: block on (state, zip3) or (state, soundex(city)) first. After blocking, you're typically comparing each HIFLD record against ~50–200 candidate ECHO records instead of all 1.7M. That's a 4-5 order-of-magnitude reduction with negligible recall loss because facilities almost never cross state lines.
Score with multiple signals
For each candidate pair, compute a composite score. Here's roughly what I'd weight:
from goldenmatch import scorer_compose, dedupe_df
from goldenflow import clean_address
# Normalize names: strip operator/agency prefixes, expand abbreviations
def normalize_facility(s: str) -> str:
s = s.upper().strip()
s = re.sub(r"^(USP|FCI|FCC|FPC|FMC|CI|CCA)\s+", "", s)
s = re.sub(r",?\s+(LLC|INC|CORP)\.?$", "", s)
return s
# Composite scorer: weighted blend
match_score = scorer_compose([
("name", "jaro_winkler", weight=0.45, preprocess=normalize_facility),
("state", "exact", weight=0.10, required=True), # hard gate
("city", "token_set_ratio", weight=0.15),
("street", "token_set_ratio", weight=0.20, preprocess=clean_address),
("zip", "exact", weight=0.05),
("latlng", "haversine_decay", weight=0.05, decay_km=5),
])
The point isn't these specific weights. The point is the join isn't one match function, it's a portfolio of weak ones. The state filter is a hard gate (no inter-state matches). Name carries ~45% of the signal. Address is a strong second when both sources have it. Lat/long is a tiebreaker, not a primary key, because of the centroid issue.
Calibrate the weights against a hand-labeled subset of 200-500 pairs. UCLA's Mississippi pilot already produced exactly this kind of labeled set (the explicit lists in issue #16). Use that as your training fold.
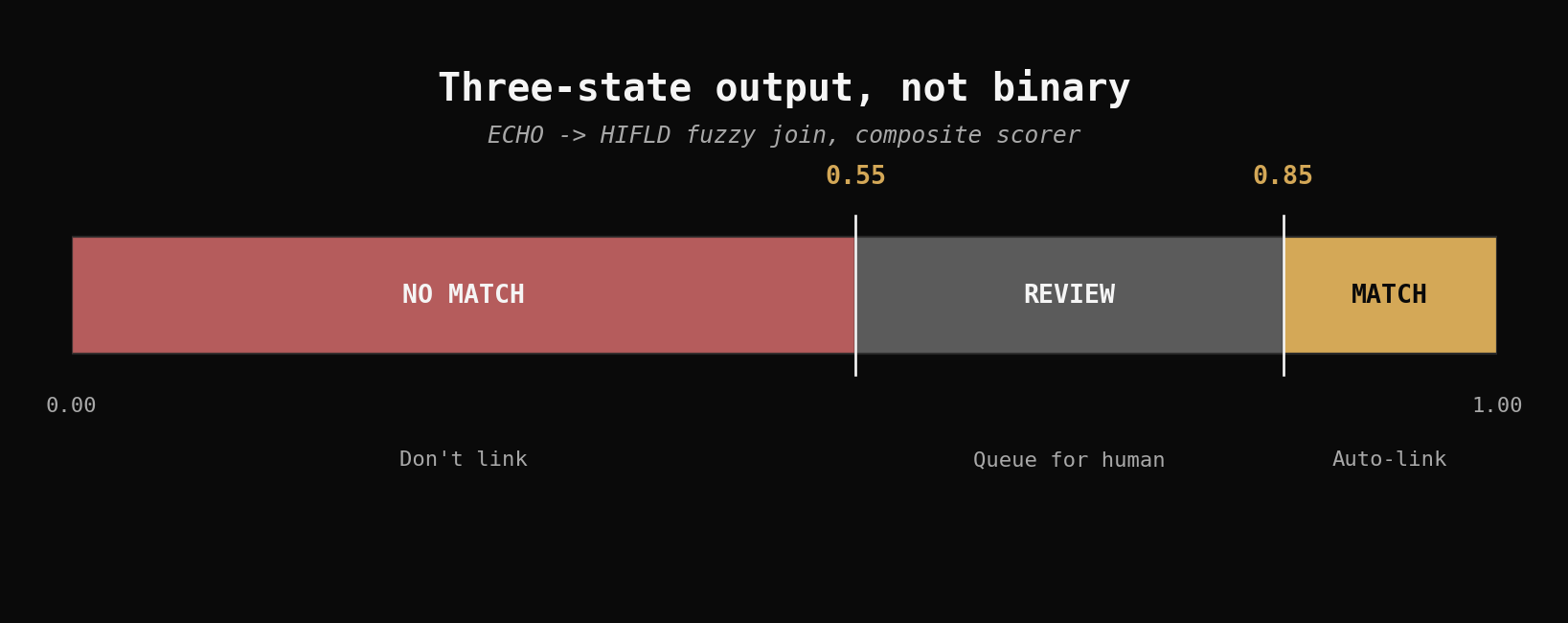
Decide with three states, not two
The output of a real ER pipeline shouldn't be binary match / no-match. There's a confidence band in the middle where the answer is "human review." Three states:
| Score range | Decision | Action |
|---|---|---|
| ≥ 0.85 | Match | Auto-link, log score |
| 0.55 to 0.85 | Review | Queue for manual disambiguation |
| < 0.55 | No match | Don't link |
For Mississippi specifically, the ~7% join rate the lab observed is suspect because a binary join can't tell you whether the missing 93% is "didn't match" (technical) or "doesn't exist in ECHO" (substantive). Three-state output untangles those: the auto-match bucket is your floor on what's matchable; the review bucket is where the registration gap from issue #2 actually lives; the no-match bucket is the floor on unregistered facilities.
This is the same AFFECTED / NOT_AFFECTED / UNDETERMINED shape I wrote about for SBOM vulnerability matching. Once you've seen it once, you see it everywhere: binary verdicts that conflate "we couldn't tell" with "we said no" are how reconciliation studies bury their own uncertainty.
The one-HIFLD-to-many-ECHO edge case
Issue #30 flags four HIFLD facilities that join to multiple Water System IDs:
hifld_facilityid PWSID REGISTRY_ID
10002476 WA5322330 110005364658
10002476 WA5327510 110005364658
10002287 NY6030008 110021747822
10002287 NY6030009 110021747822
Two questions: is this a bug or is it correct?
In SDWA, one physical facility commonly has multiple Public Water System IDs when the facility operates multiple distinct water systems. A large prison campus can have a primary potable-water system plus a separate non-potable industrial system, each with its own PWSID, both tied to the same FRS Registry ID. The fact that the REGISTRY_ID column matches across rows (110005364658 appears on both WA rows) is the tell. The EPA already knows these are the same facility from its perspective, just with multiple regulated water systems.
So the four cases in issue #30 are correct one-to-many cardinality, not duplicate matches. The way to model this in your output schema:
# Wrong: drop one or pick a "canonical" PWSID
prisons.join(sdwa, on="hifld_facilityid", how="inner").drop_duplicates(subset="hifld_facilityid")
# Right: keep the cardinality, downstream aggregations group by REGISTRY_ID or FRS_ID
prisons.join(sdwa, on="hifld_facilityid", how="inner") # row count expands intentionally
When you do per-facility roll-ups (compliance violations, inspection counts), aggregate by REGISTRY_ID not PWSID. The one-to-many is feature, not bug. Separate water systems can have separate violation histories that you actively want to surface.
This is also why I'm bearish on solving this with a spatial join. Two of the four cases in issue #30 are the same REGISTRY_ID with two PWSIDs, which a spatial join handles correctly only by accident (same lat/long, same FRS). A (name, state, address) composite scorer hitting REGISTRY_ID as the matched key is much more robust to this shape.
The FRS ID gap is a separate question
Issue #2 asks whether prisons can be registered for SDWA without an FRS ID. Short answer: yes, in two ways.
1. State-only registration. SDWA is jointly administered by EPA and state primacy agencies. A facility's water system can be regulated entirely at the state level (with a state-issued PWSID like MS1234567) without ever getting an FRS ID. The FRS is EPA's federal facility registry. State-administered systems often skip federal registration unless they cross state lines or get federal funding.
2. Registration lag. A new facility's SDWA registration can predate its FRS entry by months. The FRS is updated quarterly; state-issued PWSIDs are immediate.
Envirofacts is the right next stop. It exposes the full SDWA inventory including state-only entries that don't show up in the FRS-keyed ECHO export. The same fuzzy-join pipeline applies, just against a different source table.
What I'd want to see before quoting an F1
If I were running this engagement, the things I'd ask for:
- The current join CSV. The MS pilot output is a great start. Whatever Mississippi join you produced, I'd want to see the raw input and the labels.
- A small hand-labeled validation set. 200-500 pairs across 3-5 states with diverse facility types (federal BOP, state DOC, county jail, ICE detention, private contractor). The 7% MS finding was real but I'd want to see if it generalizes or is a Mississippi-specific quirk.
- The HIFLD pull date. HIFLD updates erratically; ECHO updates quarterly. Some of the apparent join failures will be timing artifacts.
- Operator names where available. CoreCivic, GEO Group, MTC, LaSalle Corrections. The private operator field, when present, is a strong tiebreaker because operators usually keep their own facility lists clean.
With those inputs, the right next step is a 1-day scoping pass: run the composite scorer on the MS subset, compare the auto-match bucket against the lab's ground truth, and report (a) F1 against the labels and (b) the size of the review-bucket. If the scoping pass clears 0.90 F1 on a labeled subset, you've got a defensible national pipeline. If not, the failure mode points at which signal to invest in next.
Offer
If you're someone at the lab, or honestly anyone reading this who's stuck on a similar public-records fuzzy join, send me a sample. 1k to 100k rows. I'll run it through the pipeline and send back the matched output plus the labeled disagreement set so you can see exactly where the model is confident, where it's uncertain, and where it's wrong.
The engine is open source: pip install goldenmatch. The case study I'm proudest of is Phoenix Spree Deutschland, a one-cluster walkthrough of how the same shape of problem (multi-source public records, no clean key, cross-jurisdictional) reconciles end-to-end.
ben@bensevern.dev, or open an issue on the goldenmatch repo.
Related posts
Reconciling 15 OSS Vulnerability Databases
Cross-database entity resolution across OSV, GHSA, PyPA, RustSec, and Go vulndb. 869k records, 608k canonical vulns, and one structural blind spot.
2026-04-10
Wallet Attribution at Scale: ER on 13M Blockchain Records
Running entity resolution across 10 public blockchain attribution datasets surfaces cross-jurisdictional sanctions and universal infrastructure patterns.
2026-04-09
GoldenMatch vs. BPID: Testing Against an EMNLP Benchmark
We benchmarked GoldenMatch on Amazon's BPID dataset — 10,000 adversarial PII pairs. With DOB parsing and Vertex AI embeddings, we hit 0.750 F1 — matching Ditto with zero training data.
2026-04-02